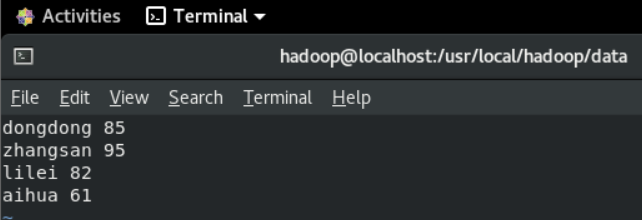
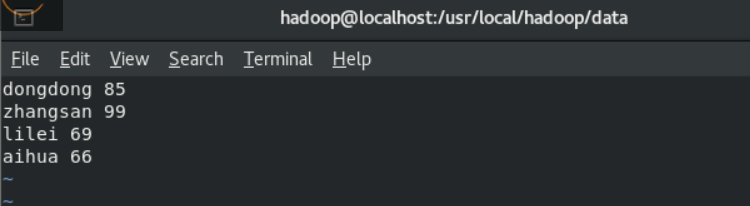
1、建立三个文档
小于 1 分钟
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/**
* map 阶段
* <p>
* Object 此处为文本数据的起始位置的偏移量;可以直接使用 Long 类型,源码此处使用Object做了泛化
* Text 输入< key, value >对的 value 值,此处为一段具体的文本数据
* Text 输出< key, value >对的 key 值,此处为一个单词
* IntWritable:输出< key, value >对的 value 值,此处固定为 1
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
// IntWritable 是 Hadoop 对 Integer 的进一步封装,使其可以进行序列化。
private final static IntWritable one = new IntWritable(1);
// map 端的任务是对输入数据按照单词进行切分,每个单词为 Text 类型。
private Text word = new Text();
/**
* @param key 输入数据在原数据中的偏移量
* @param value 具体的数据数据,此处为一段字符串
* @param context 用于暂时存储 map() 处理后的结果
* @throws IOException IO异常
* @throws InterruptedException 中断异常
*/
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// 字符串分割,也可以用 apache.common.lang3的 StringUtils.split
StringTokenizer itr = new StringTokenizer(value.toString());
// map 输出的 key value
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
/**
* reduce阶段,map的输出是reduce的输入
* Text:输入< key, value >对的key值,此处为一个单词
* IntWritable:输入< key, value >对的value值
* Text:输出< key, value >对的key值,此处为一个单词
* IntWritable:输出< key, value >对,此处为相同单词词频累加之后的值。实际上就是一个数字
*/
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
/**
* @param key 输入< key, value >对的key值,也就是一个单词
* @param values 一系列的key值相同的序列化结构
* @param context 临时存储reduce端产生的结果
* @throws IOException IO异常
* @throws InterruptedException 中断异常
*/
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
// 将相同的key进行合并,value累加
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
// 单词和它的数目
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// main函数调用Job类及逆行MapReduce 作业的初始化
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
// 设置 job 的 map 阶段的执行类
job.setMapperClass(TokenizerMapper.class);
// 设置 job 的 combine 阶段的执行类
job.setCombinerClass(IntSumReducer.class);
// 设置 job 的 reduce 阶段的执行类
job.setReducerClass(IntSumReducer.class);
// map的输出 key、value 映射
job.setOutputKeyClass(Text.class);
// 设置程序的输出的value值的类型
job.setOutputValueClass(IntWritable.class);
// 调用 addInputFormat 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
// Path 是绝对路径
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 输入文件 和 输出文件的路径
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
// 等待任务完成,任务完成之后退出程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
MapReduce采取了分而治之的基本思想,将一个大的作业分解成若干小的任务,提交给集群的多台计算机处理,这样就大大提高了完成作业的效率。
在Hadoop平台上,MapReduce框架负责处理并行编程中分布式存储、工作调度、负载均衡、容错及网络通信等复杂工作,把处理过程高度抽象为两个函数:Map 和 Reduce。
Map负责把作业分解成多个任务,Reduce负责把分解后多任务处理的结果汇总起来。
其中:
执行MapReduce作业的机器角色由两个:JobTracker 和 TaskTracker
(1)JobTracker用于调度作业(一个集群只有一个JobTracker)
(2)TaskTracker用于跟踪任务的执行情况。