1、创建一个HDFS目录
命令:hdfs dfs -mkdir -p /usr/local/hadoop/data/txtdir
截图: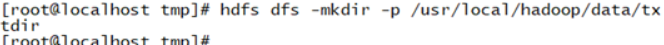
2、本地文件上传到HDFS
本地创建文件a.txt,b.txt,c.txt上传到HDFS /usr/local/hadoop/data/txtdir
命令:echo “I am student” > a.txt
小于 1 分钟
命令:hdfs dfs -mkdir -p /usr/local/hadoop/data/txtdir
截图:
本地创建文件a.txt,b.txt,c.txt上传到HDFS /usr/local/hadoop/data/txtdir
命令:echo “I am student” > a.txt
a.创建学生成绩表,结果如下。
Rowkey:id
列族:info和course,course包括3个版本数据
b.插入数据
数据包括
| 学生学号 | Info | course | |||||
|---|---|---|---|---|---|---|---|
| name | age | sex | address | Chinese | math | english | |
| 95001 | Jom | 20 | 男 | 山东省济南市 | 80 | 85 | 89 |
| 95002 | Tom | 19 | 男 | 山东省济南市 | 55,60 | 80 | 71 |
| 95003 | Lily | 20 | 女 | 北京市 | 65 |
Hive 中分区的功能是非常有用的。因为通常要对输入进行全盘扫描,来满足查询条件。
如:存储日志,log_2020_01_01、log_2020_01_02等
hive> CREATE TABLE
hive> CREATE TABLE log_2020_01_01 (id int, part string, quantity int);
hive> CREATE TABLE log_2020_01_02 (id int, part string, quantity int);
hive> CREATE TABLE log_2020_01_04 (id int, part string, quantity int);
hive> SELECT part,quantity log_2020_01_01
> UNION ALL
> SELECT part,quantity from log_2020_01_04
> WHERE quantity < 4;
Hive没有键的概念,可以对一些字段建立索引来加速某些操作,一张表的索引储存在另外一张表中。EXPLAIN命令可以查看某个查询语句是否用到了索引。
// 定义表
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
PARTITIONED BY (country STRING, state STRING); // 分区:hdfs://xxx/2020/02/20/xx
// 建立索引,仅对字段country建立索引
CREATE INDEX employees_index
ON TABLE employees(country)
// AS ... 指定索引处理器
AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
WITH DEFERRED REBUILD
IDXPROPERTIES('creator' = 'me', 'created_at' = 'some_time')
IN TABLE employees_index_table
PARTITIONED BY (country, name)
COMMENT 'Employees indexed by country and name.'
查看逻辑,更多用 EXPLAIN EXTENDED
表足够小用map-side JOIN
对于小数据集,单机或单线程执行时间比较短
hive> set oldjobtracker=${hiveconf.mapred.job.tracker};
hive> set mapred.job.tracker=local;
hive> set mapred.tmp.dir=/home/edward/tmp
hive> SELECT * from people WHERE firstname=bob;
hive> set mapred.job.tracker=${oldjobtracker};
视图可以允许保存一个查询(并)像对待表一样对这个查询进行操作。(这是一个逻辑结构,因为它不像一个表会存储数据。
当查询长且复杂,通过使用视图将这个查询语句分割成多个小的、更可控的片段可以降低这种复杂度。
例如:
改进前:Hive 查询语句中含有多层嵌套
FROM(
SELECT * FROM people JOIN cart ON (cart.people_id=people.id) WHERE firstname='john'
) a SELECT a.lastname WHERE a.id=3;
(1)cast() 函数,可以使用这个函数对指定的值进行显式的类型转换。
例如:
// 当salary字段的值是不合法的浮点数字符串的话,Hive会返回NULL
SELECT name, salary FROM employees WHERE cast(salary AS FLOAT) < 100000.0;
Hive 中 SQL JOIN 语句,只支持等值连接
内连接(INNER JOIN)中,只有进行连接的两个表中都存在于连接标准相匹配的数据才会被保留下来。不支持 >= 等不相等匹配、ON子句中谓词之间不能使用OR。
// 苹果公司股价 AAPL IBM股价IBM
// ON子句指定了两个表间数据进行连接的条件
// WHERE子句限制了左边表是AAPL的记录,右边表是IBM的记录
hive> SELECT a.ymd, a.price_close, b.price_close
>FROM stocks a JOIN stocks b ON a.ymd = b.ymd
>WHERE a.symbol = 'AAPL' AND b.symbol = 'IBM';
2010-01-04 214.01 132.45
2010-01-05 214.38 130.85
...
Hive不支持行级插入操作、更新操作和删除操作,
Hive不支持事务。
Hive 中数据库的概念本质上仅仅是表的一个目录或者命名空间。
// 1、数据库目录为:
hive.metastore.warehouse.dir
// 2、创建数据库 :
CREATE DATABASE financials;
// 3、已经存在则:
CREATE DATABASE IF NOT EXISTS financials;
// 4、查看数据库:
SHOW DATABASES; SHOW DATABASES LIKE 'f.*';
// 5、修改默数据库位置:
CREATE DATABASE financials LOCATION '/my/preferred/directory';
// 6、切换工作数据库:
USE financials;
(Hive v0.8.0,可以修改当前工作数据库为默认数据库,set hive.cli.print.current.db=true;)
// 7、删除数据库:
DROP DATABASE IF EXISTS financials;