1、创建一个HDFS目录
命令:hdfs dfs -mkdir -p /usr/local/hadoop/data/txtdir
截图: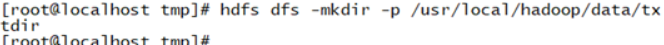
2、本地文件上传到HDFS
本地创建文件a.txt,b.txt,c.txt上传到HDFS /usr/local/hadoop/data/txtdir
命令:echo “I am student” > a.txt
小于 1 分钟
命令:hdfs dfs -mkdir -p /usr/local/hadoop/data/txtdir
截图:
本地创建文件a.txt,b.txt,c.txt上传到HDFS /usr/local/hadoop/data/txtdir
命令:echo “I am student” > a.txt
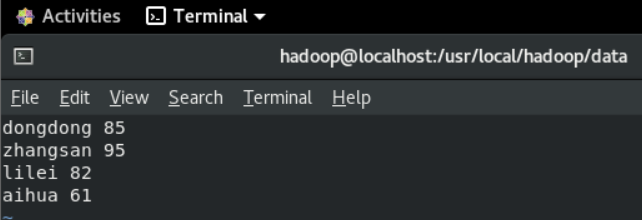
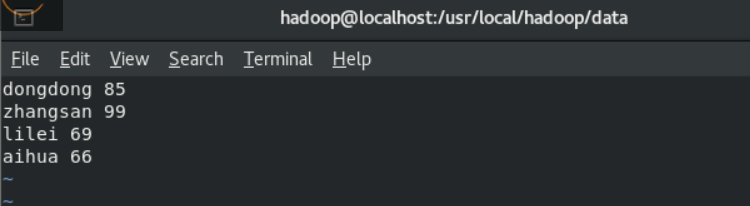
a.创建学生成绩表,结果如下。
Rowkey:id
列族:info和course,course包括3个版本数据
b.插入数据
数据包括
| 学生学号 | Info | course | |||||
|---|---|---|---|---|---|---|---|
| name | age | sex | address | Chinese | math | english | |
| 95001 | Jom | 20 | 男 | 山东省济南市 | 80 | 85 | 89 |
| 95002 | Tom | 19 | 男 | 山东省济南市 | 55,60 | 80 | 71 |
| 95003 | Lily | 20 | 女 | 北京市 | 65 |
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/**
* map 阶段
* <p>
* Object 此处为文本数据的起始位置的偏移量;可以直接使用 Long 类型,源码此处使用Object做了泛化
* Text 输入< key, value >对的 value 值,此处为一段具体的文本数据
* Text 输出< key, value >对的 key 值,此处为一个单词
* IntWritable:输出< key, value >对的 value 值,此处固定为 1
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
// IntWritable 是 Hadoop 对 Integer 的进一步封装,使其可以进行序列化。
private final static IntWritable one = new IntWritable(1);
// map 端的任务是对输入数据按照单词进行切分,每个单词为 Text 类型。
private Text word = new Text();
/**
* @param key 输入数据在原数据中的偏移量
* @param value 具体的数据数据,此处为一段字符串
* @param context 用于暂时存储 map() 处理后的结果
* @throws IOException IO异常
* @throws InterruptedException 中断异常
*/
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// 字符串分割,也可以用 apache.common.lang3的 StringUtils.split
StringTokenizer itr = new StringTokenizer(value.toString());
// map 输出的 key value
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
/**
* reduce阶段,map的输出是reduce的输入
* Text:输入< key, value >对的key值,此处为一个单词
* IntWritable:输入< key, value >对的value值
* Text:输出< key, value >对的key值,此处为一个单词
* IntWritable:输出< key, value >对,此处为相同单词词频累加之后的值。实际上就是一个数字
*/
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
/**
* @param key 输入< key, value >对的key值,也就是一个单词
* @param values 一系列的key值相同的序列化结构
* @param context 临时存储reduce端产生的结果
* @throws IOException IO异常
* @throws InterruptedException 中断异常
*/
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
// 将相同的key进行合并,value累加
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
// 单词和它的数目
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// main函数调用Job类及逆行MapReduce 作业的初始化
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
// 设置 job 的 map 阶段的执行类
job.setMapperClass(TokenizerMapper.class);
// 设置 job 的 combine 阶段的执行类
job.setCombinerClass(IntSumReducer.class);
// 设置 job 的 reduce 阶段的执行类
job.setReducerClass(IntSumReducer.class);
// map的输出 key、value 映射
job.setOutputKeyClass(Text.class);
// 设置程序的输出的value值的类型
job.setOutputValueClass(IntWritable.class);
// 调用 addInputFormat 设置输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
// Path 是绝对路径
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 输入文件 和 输出文件的路径
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
// 等待任务完成,任务完成之后退出程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Yarn的基本思想是将 JobTracker 的资源管理和作业的调度/监控两大主要职能拆分为两个独立的进程:
a. 一个全局的 Resource Manager
b. 每个应用对应的 Application Master(AM)
Resource Manager 和每个节点上的 Node Manager(NM)组成了全新的通用操作系统,以分布式的方式管理应用程序。
Resource Manager拥有为系统中所有应用分配资源的决定权。与之相关的是应用程序的Application Master,负责与Resource Manager协商资源,并与Node Manager协同工作来执行和监控任务。
HDFS有一个文件系统实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件。
HDFS通过RPC调用NameNode获取文件块的位置信息,对于文件的每一个块,NameNode会返回该块副本DataNode的节点地址。
另外,客户端还会根据网络拓扑来确定它与每一个DataNode的位置信息,从离它最近的那个DataNode获取数据块的副本,最理想的情况是数据块就储存在客户端所在的节点上。
具体过程:
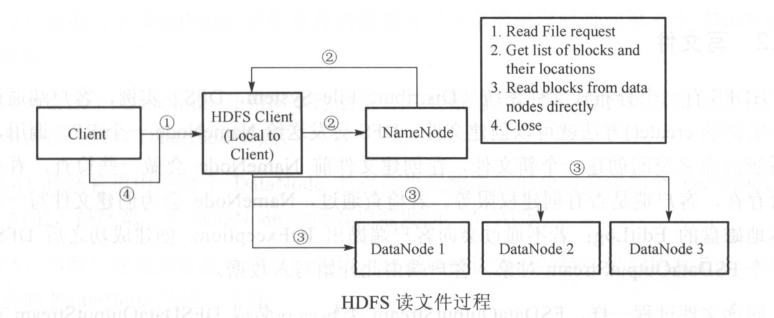
(1)客户端发起请求
(2)客户端与NameNode得到文件的块及位置信息列表
(3)客户端直接和DataNode交互读取数据
(4)读取完成关闭连接
这样设计的巧妙之处有:
(1)在运行MapReduce任务时,每个客户端就是一个DataNode节点。
(2)NameNode 仅需要相应块的位置信息请求,否则随着客户端的增加,NameNode会很快成为瓶颈。
Hadoop的网络拓扑。在海量数据处理过程中,主要限制因素时节点之间的带宽。衡量两个节点之间的带宽往往很难实现,在这里Hadoop采取了一个简单的方法,它把网络拓扑看成一棵树,两个节点的距离等于他们到最近共同祖先距离的综合,而树的层次可以这么划分:
a、同一个节点中的进程
b、同一机架上的不同节点
c、同一数据中心不同机架
d、不同数据中心的节点
本文权威指南读书笔记
(1)存储大文件:HDFS支持GB级别大小的文件;
(2)流式数据访问:保证高吞吐量
(3)容错性:完善的冗余备份机制;
(4)简单的一致性模型:一次写入多次读取;
(5)移动计算优于移动数据:HDFS使应用计算移动到离他最近数据位置的接口;
(6)兼容各种硬件和软件平台。
HDFS不适合的场景:
(1)大量小文件:文件的元数据存储在NameNode内容中,大量小文件意味着元数据增加,会占用大量内存;
(2)低延迟数据访问:HDFS是专门针对吞吐量而不是用户低延迟;
(3)多用户写入:导致一致性维护困难。
MapReduce采取了分而治之的基本思想,将一个大的作业分解成若干小的任务,提交给集群的多台计算机处理,这样就大大提高了完成作业的效率。
在Hadoop平台上,MapReduce框架负责处理并行编程中分布式存储、工作调度、负载均衡、容错及网络通信等复杂工作,把处理过程高度抽象为两个函数:Map 和 Reduce。
Map负责把作业分解成多个任务,Reduce负责把分解后多任务处理的结果汇总起来。
其中:
执行MapReduce作业的机器角色由两个:JobTracker 和 TaskTracker
(1)JobTracker用于调度作业(一个集群只有一个JobTracker)
(2)TaskTracker用于跟踪任务的执行情况。