MapReduce概述
大约 3 分钟
一、基本模型
MapReduce采取了分而治之的基本思想,将一个大的作业分解成若干小的任务,提交给集群的多台计算机处理,这样就大大提高了完成作业的效率。
在Hadoop平台上,MapReduce框架负责处理并行编程中分布式存储、工作调度、负载均衡、容错及网络通信等复杂工作,把处理过程高度抽象为两个函数:Map 和 Reduce。
Map负责把作业分解成多个任务,Reduce负责把分解后多任务处理的结果汇总起来。
其中:
执行MapReduce作业的机器角色由两个:JobTracker 和 TaskTracker
(1)JobTracker用于调度作业(一个集群只有一个JobTracker)
(2)TaskTracker用于跟踪任务的执行情况。
二、wordcount
统计所有文件中每一个单词出现的次数(频次)。
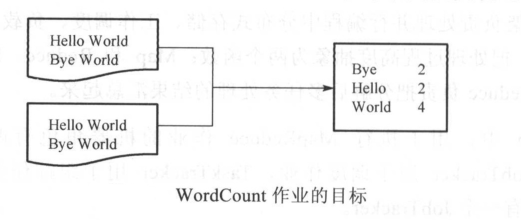
所做的操作:
(1)拆分输入数据
拆分数据 属于 Map 的输入阶段,系统会逐行读取文件的数据,得到一系列的(key/value)
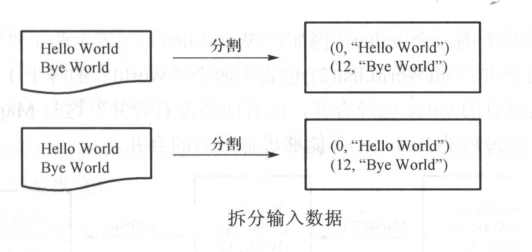
注意:如果只有一个文件,且很小,系统只分配一个Split;
如果由多个文件,或者文件很大,多个Split
上图 0、12为偏移量(包含回车)即:H是第0个字符 B是第12个字符
(2)执行Map方法
分割完成后,系统会将分割好的(key/value)对交给用户定义的 Map 方法进行处理,生成新的(key/value)对
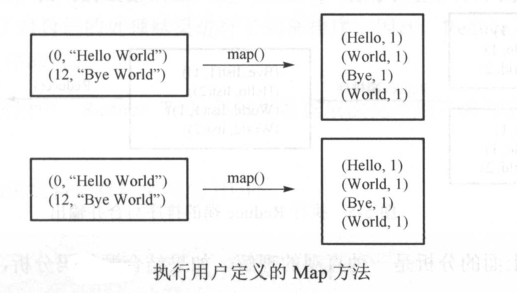
注意:后边这个1是个数
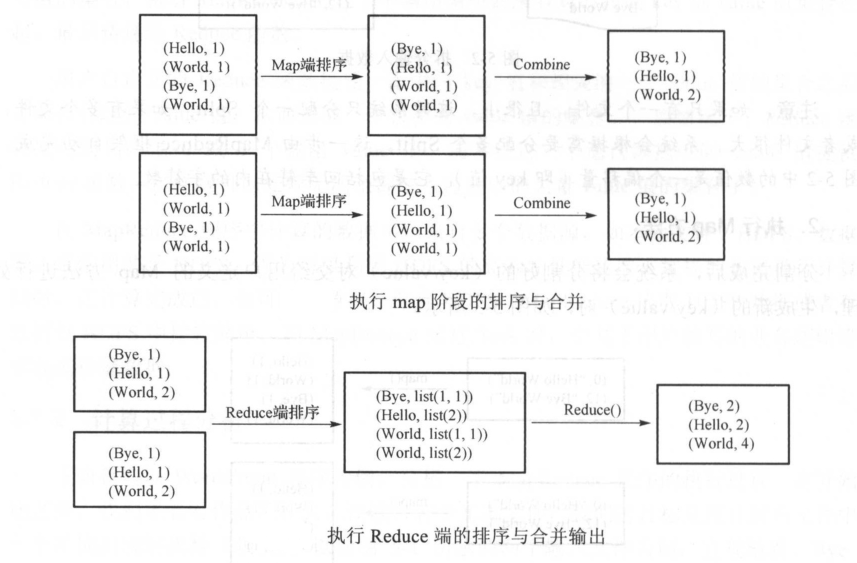
(3)排序与合并处理
系统得到Map方法输出的(key/value)对后,Mapper 会将它们按照 key 值进行排序,并执行Combine 过程,将 key 值相同的 value 值累加,得到 Mapper 的最终输出结果。
即:先排序 后累加
(4)Reduce 阶段的排序与合并
Reducer 先对从 Mapper 接收的数据进行排序,再交由用户自定义的 Reduce 方法进行处理,得到新的(key/value)对,并作为WordCount的结果输出
简述上述过程:
(A)Map
(a)Read:
Map Task 通过用户编写的 RecordReader,从输入 InputSplit 中解析出多个(key/value)
(b)Map:
将解析出的(key/value)交给用户编写的Map函数处理,并产生一系列新的(key/value)
(c)Collect:
在用户编写的Map函数中,数据处理完成后,一般会调用OutputCollector.collect()收集结果。在该函数内部,它会将生成(key/value)分片(通过Partitioner),并写入一个环形内存缓冲区中。(感觉像
,log4j2用的队列)
(d)Spill:
环形缓冲区填满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。将数据写入本地磁盘之前,先对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
(e)Combine:
当所有数据处理完成后,Map Task 对所有临时文件进行一次合并,以确保最终只会生成一个数据文件
(B)Reduce
(a)Shuffle:
也成为Copy。Reduce Task从各个Map Task上远程复制一片数据,并针对某一篇数据进行判断,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(b)Merge:
在远程复制的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘上文件过多。(为啥要用两个线程呢?)
(c)Sort:
按照MapReduce语义,用户编写的 Reduce 函数输入数据时按 key 进行聚集的一组数据。(采用基于排序的策略)。各个Map Task实现了局部排序,Reduce Task只需对所有的数据进行一次归并排序即可。
(d)Reduce:
Reduce Task将每组数据一次交给用户编写的 reduce()函数处理
(e)Write:
reduce()函数将计算结果写到HDFS