mysql表设计及优化
一、一些建议
建议来自《MYSQL 王者晋级之路》,本文做些笔记
1)在创建业务表时,库名、表名、字段名必须使用小写字母,采用 “_” 分割。
2)mysql数据库中,通过lower_case_table_names参数来区别表名的大小写,默认为0,代表大小写敏感。如果是1,代表大小写不敏感,以小写存储。为字段选取数据类型时,要秉承着简单、够用的原则。表中的字段和索引数量都不宜过多,要保证SQL语句查询的高效性,快速执行完,避免出现堵塞、排队现象。
3)表的存储引擎一定要选择使用InnoDB。mysql 5.7基本已经废弃 MyISAM,8.0后彻底废弃。
4)要显式地为表创建一个使用自增列 INT 或者 BIGINT 类型作为主键,可以保证写入顺序是自增的,和B+tree叶子节点分裂顺序一致。写入更加高效,TPS性能会更高,存储效率也是最高的。
5)金钱、日期时间、IPV4尽量使用 int 来存储。用 int 来存储金钱,让 int 单位为分,这样就不存在四舍五入了,存储的数值更加准确。
日期可以选择使用datetime,datetime的可用范围比timestamp大,物理存储上仅比timestamp 多占 1 个字节多的空间,整体性能上的消耗并不算太大。因此在生产环境可以使用datetime时间类型。当然也可以使用 int 来存储时间,通过转换函数 from_unixtime 和 unix_timesstamp来实现。
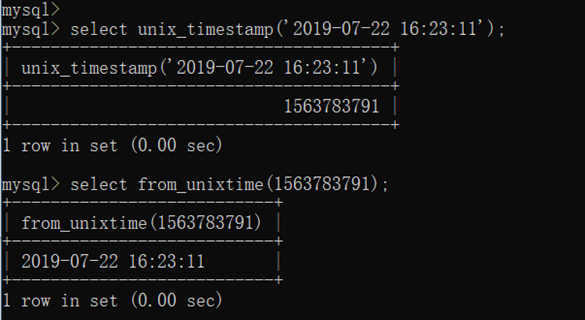
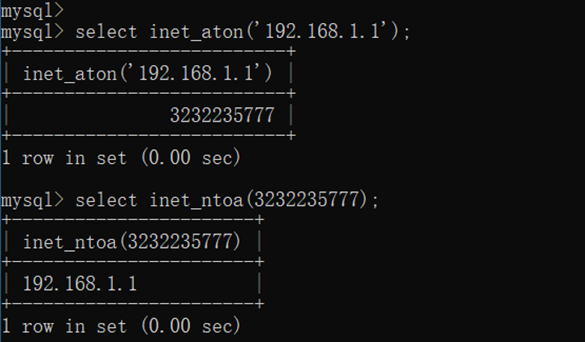
IPV4字段基本上可以不适用char(15)来存储,使用int来存储,通过转换函数 inet_aton 和 inet_ntoa来实现。
有些字段比如性别sex字段、状态status字段,基本上选择tinyint就可以。
有时候精确计算使用decimal,设计sum等统计数据时候
6)text 和 blob 这种存大量文字或者存图片的大数据类型,建议不要和业务表放在一起。
注:主要业务表切忌出现这样大类型的字段。
SQL语句中尽量避免出现 or 子句,这种判断的子句可以让程序自动完成,不要交给数据库判断。也要避免使用union,尽量采用union all,减少去重和排序的工作。
7)用 select 查询表时只需要获取必要的字段,避免使用 select *。这样可以减少网络带宽的消耗,还有可能利用到覆盖索引。
建立索引时不要在选择性低的字段上创建,比如sex、status这种字段。
索引的选择性计算方法:
select count(distinct coll) / count(*) from table_name; // 越接近 1 ,证明选择性越高,越适合创建索引。
sum()函数容易返回null值,记得处理
8)很长的字符串可以考虑创建前缀索引,提高索引利用率。
单表索引数量不要太多,一般建议不要超过 4~5个(根据实际业务表再确定)。当执行DML语句操作时,也会索引进行更新,如果索引数量太多,则会造成索引树的分裂,性能也会下降。
9)所有字段定义中,默认都加上 not null 约束,避免出现 null 。在对该字段进行 select count() 统计计数时,可以让统计结果更准确,因为值为null的数据不会被计算进去。
10)表的字符集默认使用 UTF-8 ,必要时可申请使用 UTF8mb4 字符集。因为它的通用性比 GBK 、Latin1 都要好。UTF8字符集存储汉子占用3个字节,如果遇到表情储存的需求,就可以使用UTF8mb4
11)建议模糊查询 select...like '%**%' 的语句不要出现在数据库中,可以使用搜索引擎sphinx代替。
12)索引字段上面不要使用函数,否则使用不到索引,也不要创建函数索引。
13)join列类型要保持一致,其中包括长度、字符集都要一致。?https://blog.csdn.net/n88Lpo/article/details/78099114
14)当在执行计划中的 extra 项看到 Using filesort,或者看到 Using temporary 时,也要优先考虑创建排序索引和分组索引。(排序、分组字段上都要创建索引)
15)limit 语句上的优化,建议使用主键来进行范围检索,缩短结果集大小,使查询效率更高效。
二、算是面试题吧
1)为什么一定要设一个主键?
因为在不设置主键的情况下,innodb也会自动生成一个隐藏列,作为自增主键。
所以自己显示指定更可以清晰的看出主键id。
2)主键是自增还是UUID?
自增。innodb中的主键是聚簇索引。如果是自增的主键,插入数据时不会引发页分裂。性能更高。
3)主键为什么不推荐有业务含义?
倘若主键变更会引发很多麻烦;引发页分裂。
4)表示枚举的字段为什么不用enum类型?
枚举字段一般用tinyint类型。因为enum类型order by效率低,而且插入阿拉伯数字有问题。
5)为什么不直接存储图片、音频、视频等大容量内容?
在实际应用中,使用HDFS来存储文件。mysql只用来存储下载地址。
当存文件的时候,比如Base64加密文件等,排序不能使用内存临时表(OOM),必须使用磁盘的临时表,导致查询缓慢;binlog太多,导致主从的效率问题。
所以,不推荐使用text和blob类型。
6)字段为什么要定义NOT NULL DEFAULT ?
有null,count(包含null的列)会出现问题。而且影响索引的性能
7)看建表语法
mysql> ? create table
8)Mysql存储引擎
MyISAM、 InnoDB、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、 ARCHIVE、CSV、BLACKHOLE、FEDERATED。
Tips: InnoDB和BDB提供事务安全表,其他存储引擎都是非事务安全表。
9)常用的2种存储引擎?
1、Myisam是Mysql的默认存储引擎,当create创建新表时,未指定新表的存储引擎时,默认使用Myisam。每个MyISAM 在磁盘上存储成三个文件。
文件名都和表名相同,扩展名分别是 .frm (存储表定义) MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。数据文件和索引文件可以放置在不同的目录,平均分布io,获得更快的速度。
2、InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比 Myisam 的存储引擎,InnoDB 写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
10)可以针对表设置引擎吗?如何设置?
可以, ENGINE=xxx 设置引擎。
代码示例:
create table person(
id int primary key auto_increment,
username varchar(32)
) ENGINE=InnoDB
11)选择合适的存储引擎?
选择标准: 根据应用特点选择合适的存储引擎,对于复杂的应用系统可以根据实际情况选择 多种存储引擎
进行组合. 下面是常用存储引擎的适用环境:
- MyISAM:默认的 mysql 插件式存储引擎, 它是在 Web、 数据仓储和其他应用环境下最常使用的存
储引擎之一。
InnoDB:用于事务处理应用程序,具有众多特性,包括 ACID 事务支持。
Memory: 将 所有数据保存在RAM 中, 在 需要快速查找引用和其他类似数据的环境下,可 提供极快的访问。
Merge:允许 mysql DBA 或开发人员将一系列等同的 MyISAM 表以逻辑方式组合在一起,并作为 1个对象引用它们。对于诸如数据仓储等 VLDB 环境十分适合。
12)选择合适的数据类型
前提: 使用适合存储引擎。
选择原则: 根据选定的存储引擎,确定如何选择合适的数据类型下面的选择方法按存储引擎分类 :
MyISAM 数据存储引擎和数据列
MyISAM数据表,最好使用固定长度的数据列代替可变长度的数据列。
MEMORY存储引擎和数据列
MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关
系。两者都是作为CHAR类型处理的。
InnoDB 存储引擎和数据列
建议使用 VARCHAR类型
对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行 都使用指向数
据列值的头指针) ,因此在本质上,使用固定长度的CHAR列不一定比使 用可变长度VARCHAR列简
单。 因而, 主要的性能因素是数据行使用的存储总量。 由于 CHAR 平均占用的空间多于
VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总 量和磁盘I/O是比较好的。
13)char & varchar
保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不
进行大小写转换。
14)Mysql字符集
mysql服务器可以支持多种字符集 (可以用show character set命令查看所有mysql支持 的字符集) ,在
同一台服务器、同一个数据库、甚至同一个表的不同字段都可以指定使用不 同的字符集。
mysql的字符集包括字符集(CHARACTER)和校对规则(COLLATION)两个概念。
15)索引设计原则?
- 搜索的索引列:不 一定是所要选择的列。最适合索引的列是出现在WHERE子句中的列,或连接子
句中指定的列,而不是出现在SELECT 关键字后的选择列表中的列。
- 使用惟一索引:考虑某列中值的分布。 对于惟一值的列,索引的效果最好,而具有多个 重复值的
列,其索引效果最差。
- 使用短索引:如果对串列进行索引,应该指定一个前缀长度,只要有可能就应该这做样。 例如,如
果有一个 CHAR(200) 列,如果在前 10 个或 20 个字符内,多数值是惟一的, 那么就不要对整个列
进行索引。
- 利用最左前缀:在创建 一个 n 列的索引时,实际是创建了 mysql 可利用的 n 个索引。 多列索引
可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。 这样的列集 称为最左前缀。 (这
与索引一个列的前缀不同,索引一个列的前缀是利用该的n前个字 符作为索引值 )
- 不要过度索引:每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能,这一点我们前面
已经介绍 过。在修改表的内容时,索引必须进行更新,有时可能需要重构, 因此, 索引越多,所花的
时间越长。
如果有一个索引很少利用或从不使用,那么会不必要地减缓表的修改速度。 此外,mysql 在生成
一个执行计划时,要考虑各个索引,这也要费时间。
创建多余的索引给查询优化带来了更多的工作。索引太多,也可能会使 mysql选择不到所要使用
的 最好索引。 只保持所需的索引有利于查询优化。 如果想给已索引的表增加索引, 应 该考虑所要
增加的索引是否是现有多列索引的最左索引。
- 考虑在列上进行的比较类型: 索引可用于“ <”、“ < = ”、“ = ”、“ > =”、“ > ”和 BETWEEN 运算。在
模式具有一个直接量前缀时,索引也用于 LIKE 运算。如果只将某个列用于其他类型的运算时(如
STRCMP( )) ,对其进行索引没有价值。
16)MySql有哪些索引?
数据结构角度
BTREE
HASH
FULLTEXT
R-Tree
物理存储角度
1、聚集索引(clustered index)
2、非聚集索引(non-clustered index)
从逻辑角度
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
17)Hash索引和B+树索引的底层实现原理
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。
B+树底层实现是多路平衡查找树,对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
那么可以看出他们有以下的不同:
hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。
而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
hash索引不支持使用索引进行排序,原理同上。
hash索引不支持模糊查询以及多列索引的最左前缀匹配.原理也是因为hash函数的不可预测。
AAAA和AAAAB的索引没有相关性。
hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
hash索引虽然在等值查询上较快,但是不稳定.性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。
而不需要使用hash索引
18)非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行
select age from employee where age < 20
的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询.
19)如何避免回表查询?什么是索引覆盖?
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
select * from t where name='lisi';
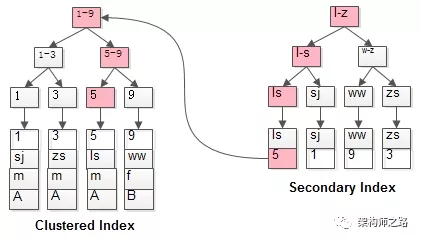
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
都能够命中就是索引覆盖,无需回表。
20)事务4个特性?
事务是必须满足4个条件(ACID):
原子性 Atomicity:一个事务中的所有操作,要么全部完成,要么全部不完成,最小的执行单位。
一致性 Consistency:事务执行前后,都处于一致性状态。
隔离性 Isolation:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防
止多个事务并发执行时由于交叉执行而导致数据的不一致。
持久性 Durability:事务执行完成后,对数据的修改就是永久的,即便系统故障也不会丢失。
21)事务隔离级别分别是?
READ_UNCOMMITTED 这是事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。解决第一类丢失更新的问题,但是会出现脏读、不可重复读、第二类丢失更新的问题,幻读 。
READ_COMMITTED 保证一个事务修改的数据提交后才能被另外一个事务读取,即另外一个事务不能读取该事务未提交的数据。解决第一类丢失更新和脏读的问题,但会出现不可重复读、第二类丢失更新的问题,幻读问题
REPEATABLE_READ 保证一个事务相同条件下前后两次获取的数据是一致的 (注意是 一个事务,可以理解为事务间的数据互不影响)解决第一类丢失更新,脏读、不可重复读、第二类丢失更新的问题,但会出幻读。
SERIALIZABLE 事务串行执行,解决了脏读、不可重复读、幻读。但效率很差,所以实际中一般不用。
22)InnoDB默认事务隔离级别?如何查看当前隔离级别
可重复读(REPEATABLE-READ)
查看:
mysql> select @@global.tx_isolation;
+———————————+ |
@@global.tx_isolation
| +———————————+ |
REPEATABLE-READ |
+———————————+
1 row in set, 1 warning (0.01 sec)
23)如何查看表结构?
mysql> desc zipkin_spans;
24)Mysql删除表的几种方式?区别?
1.delete : 仅删除表数据,支持条件过滤,支持回滚。记录日志。因此比较慢。
delete from table_name;
2.truncate: 仅删除所有数据,不支持条件过滤,不支持回滚。不记录日志,效率高于delete。
truncate table table_name;
3.drop:删除表数据同时删除表结构。将表所占的空间都释放掉。删除效率最高。
drop table table_name;
25)主键和唯一索引区别?
本质区别,主键是一种约束,唯一索引是一种索引。
主键不能有空值(非空+唯一),唯一索引可以为空。
主键可以是其他表的外键,唯一索引不可以。
一个表只能有一个主键,唯一索引 可以多个。
都可以建立联合主键或联合唯一索引。
主键->聚簇索引,唯一索引->非聚簇索引。
主键和唯一索引区别?
本质区别,主键是一种约束,唯一索引是一种索引。
主键不能有空值(非空+唯一),唯一索引可以为空。
主键可以是其他表的外键,唯一索引不可以。
一个表只能有一个主键,唯一索引 可以多个。
都可以建立联合主键或联合唯一索引。
主键-》聚簇索引,唯一索引->非聚簇索引。
26、查看当前表有哪些索引?
show index from table_name;
27、索引不生效的情况?
使用不等于查询。
NULL值。
列参与了数学运算或者函数。
在字符串like时左边是通配符.比如 %xxx。
当mysql分析全表扫描比使用索引快的时候不使用索引。
当使用联合索引,前面一个条件为范围查询,后面的即使符合最左前缀原则,也无法使用索引。
28、explain列有哪些?含义?
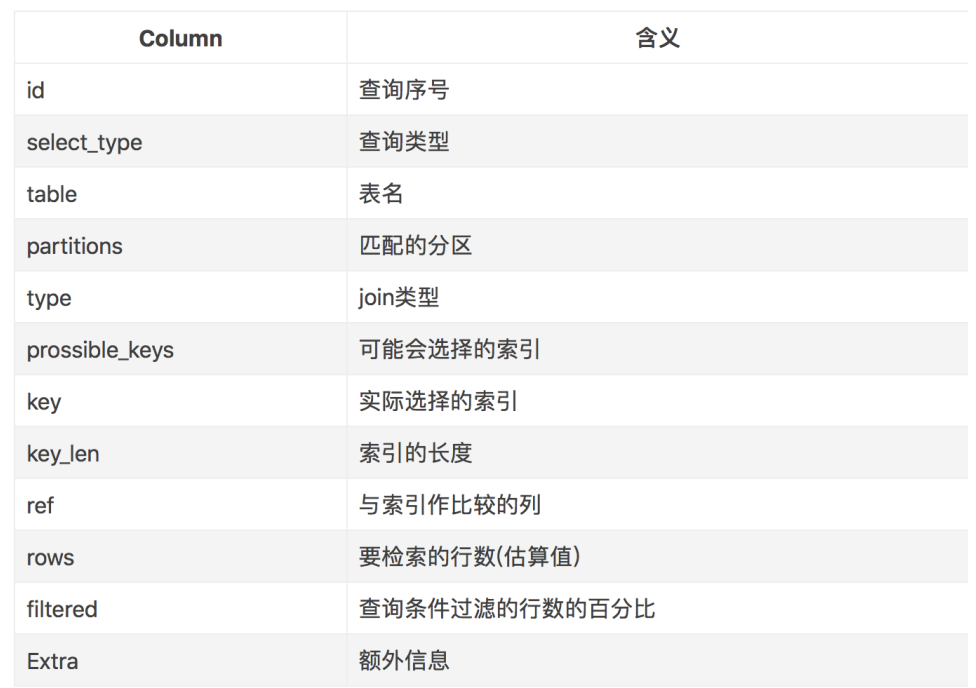
1、 id
SQL查询中的序列号。
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行。
2、select_type
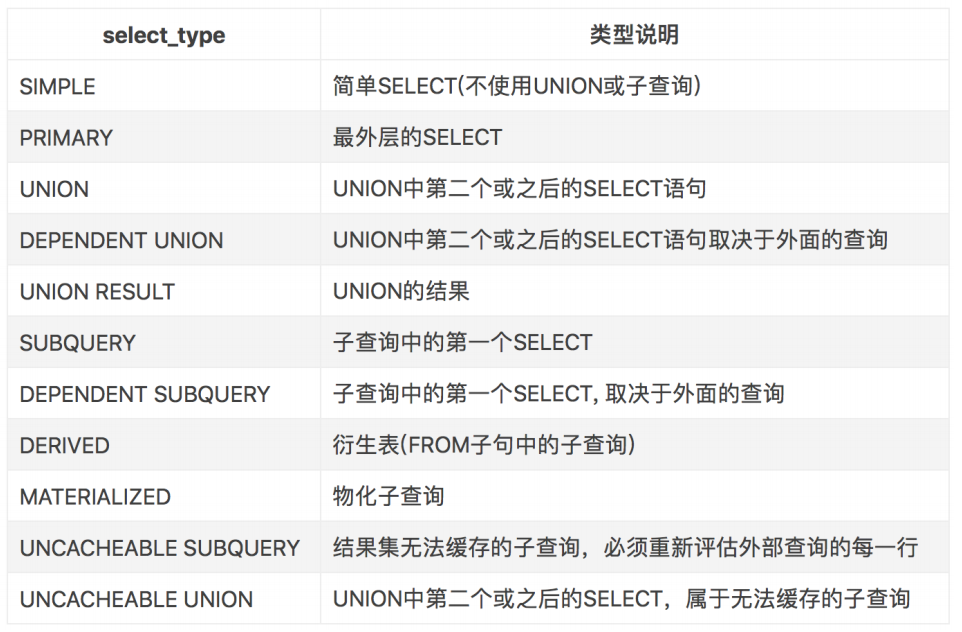
3、table
显示这一行的数据是关于哪张表的。不一定是实际存在的表名。 可以为如下的值:<unionM,N>: 引用id为M和N UNION后的结果。
引用id为N的结果派生出的表。派生表可以是一个结果集,例如派生自FROM中子查询的结果。
引用id为N的子查询结果物化得到的表。即生成一个临时表保存子查询的结果。
4、type
这是最重要的字段之一,显示查询使用了何种类型。从最好到最差的连接类型依次为:
system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,
index_subquery,range,index,ALL
explain结果每个字段的含义说明 - 简书 (jianshu.com)
29、MySql最多创建多少列索引?
16
30、varchar(10)和int(10)代表什么含义
varchar的10代表了申请的空间长度,也是可以存储的数据的最大长度,而int的10只是代表了展示的长度,
不足10位以0填充.也就是说,int(1)和int(10)所能存储的数字大小以及占用的空间都是相同的,只是在展示
时按照长度展示。
31、count(*)在不同引擎的实现方式?
MyISAM :把一个表的总行数存在了磁盘上,执行 count(*) 的时候会直接返回这个数,效率很高。
InnoDB : 比较麻烦,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计
数
三、数据结构
需要了解mysql的数据结构才能更加清楚上述效率的问题,请看数据结构篇~~