ElasticSearch近实时性介绍
大约 2 分钟
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
Elasticsearch 是一款功能强大的分布式搜索引擎,支持近实时的存储、搜索数据。
Elasticsearch和磁盘之间是文件系统缓存,在内存索引缓冲区中的文档 会被写入到一个新的段中 ,但是这里新段会被先写入到文件系统缓存,这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
图1、在内存缓冲区中包含了新文档的 Lucene 索引
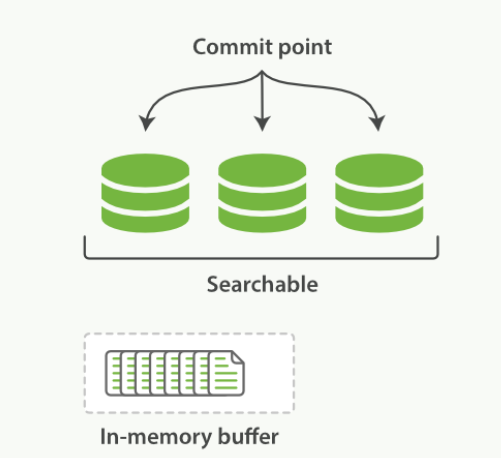
Lucene 允许新段被写入和打开,使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
图2、缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交
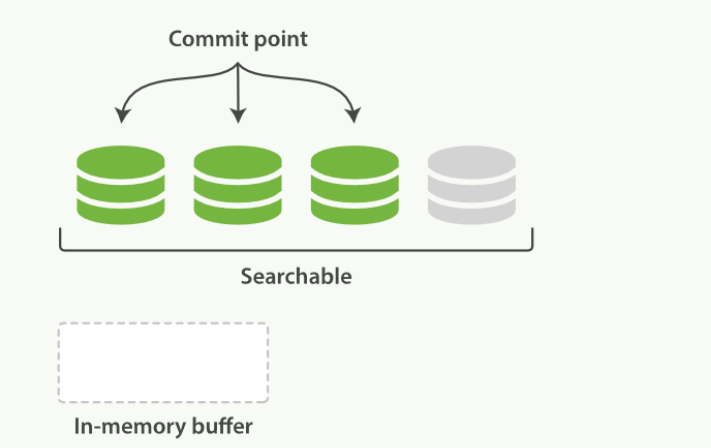
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 *refresh* 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 *近* 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。