Hive数据操作(1)
大约 4 分钟
一、加载数据
Hive 没有行级别的数据插入、数据更新和删除操作,那么网表中装载数据的唯一途径就是使用一种 “ 大量 ” 的数据装载操作。或者通过其他方式仅仅将文件写入到正确的目录下。
// OVERWRITE关键字换成INTO关键字的话,Hive将会以追加的方式写入数据而不会覆盖之前已经存在的内容
LOAD DATA LOCAL INPATH '${env:HOME}/california-employees'
OVERWRITE INTO TABLE employees
// 非分区表省略此行
PARTITION (country = 'US', state = 'CA')
如果分区目录不存在的话,会先创建分区目录,然后再将数据拷贝到该目录下。
二、设置分区
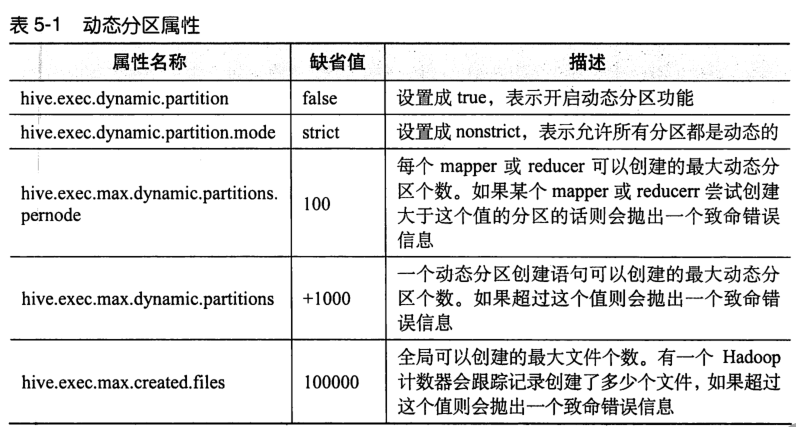
上表为动态分区属性,如果不小心按照秒分区,每秒建立一个分区,则十分浪费资源,设置hive.exec.max.dynamic.partitions可以创建最大动态分区个数,如果超过这个值就会抛出一个致命错误。
设置分区的方式
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> set hive.exec.max.dynamic.partitions.pernode=1000;
hive> INSERT OVERWRITE TABLE employees
> PARTITION (country, state)
> PARTITION ..., se.cty, se.st
> FROM staged_employees se;
三、单个查询语句中创建表并加载数据
CREATE TABLE ca_employees
AS SELECT name, salary, address
FROM employees WHERE se.state = 'CA';
四、导出数据
//(1)直接拷贝文件夹
hadoop fs -cp source_path DIRECTORY '/tmp/ca_employees'
//(2)或者用INSERT ... DICTORY ...,
// 也可以写成全路径 hdfs://master-server/tmp/ca_employees
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/ca_employees'
SELECT name, salary, adress
FROM employees
WHERE se.state = 'CA';
五、HiveQL 查询
SELECT是SQL中的映射算子,指定了要保存的列以输出函数需要调用的一个或多个列;
FROM子句标识了从哪个表、试图或嵌套查询中选择记录。
// 查询ARRAY的第一个元素
SELECT name, subordinates[0] FROM employees;
// 查询键值
SELECT name, deductions["State Taxes"] FROM employees;
// 查询一个元素,也可以用 ‘点’
SELECT name, address.city FROM employees;
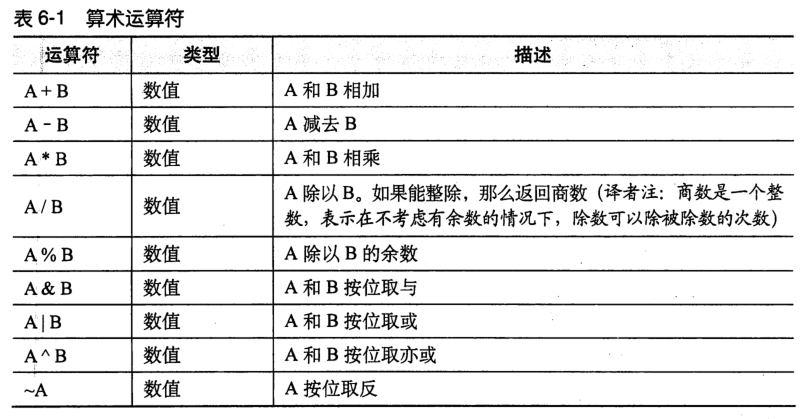
(1)Hive支持的算数运算符
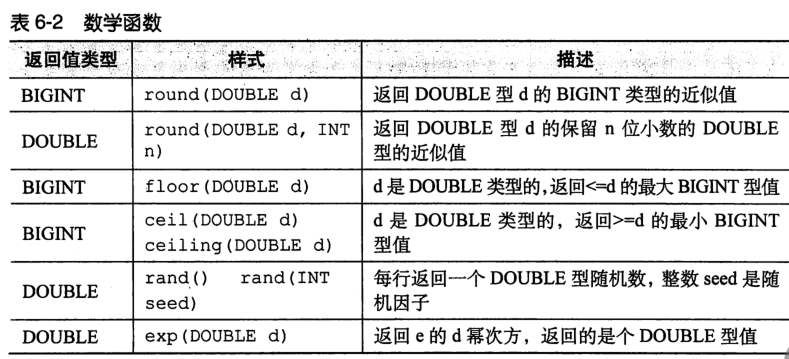
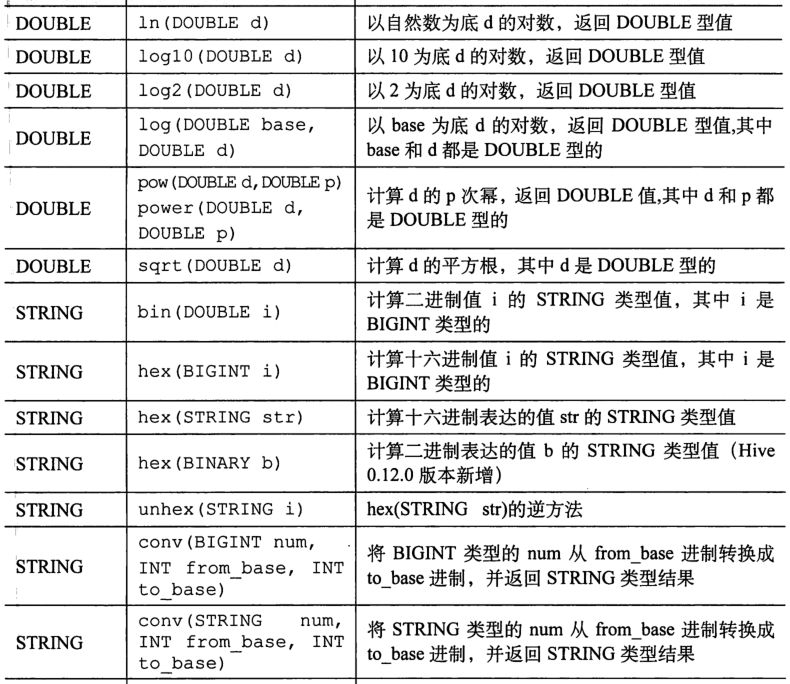
(2)Hive 内置数学函数


(3)Hive聚合函数
最有名的是count avg
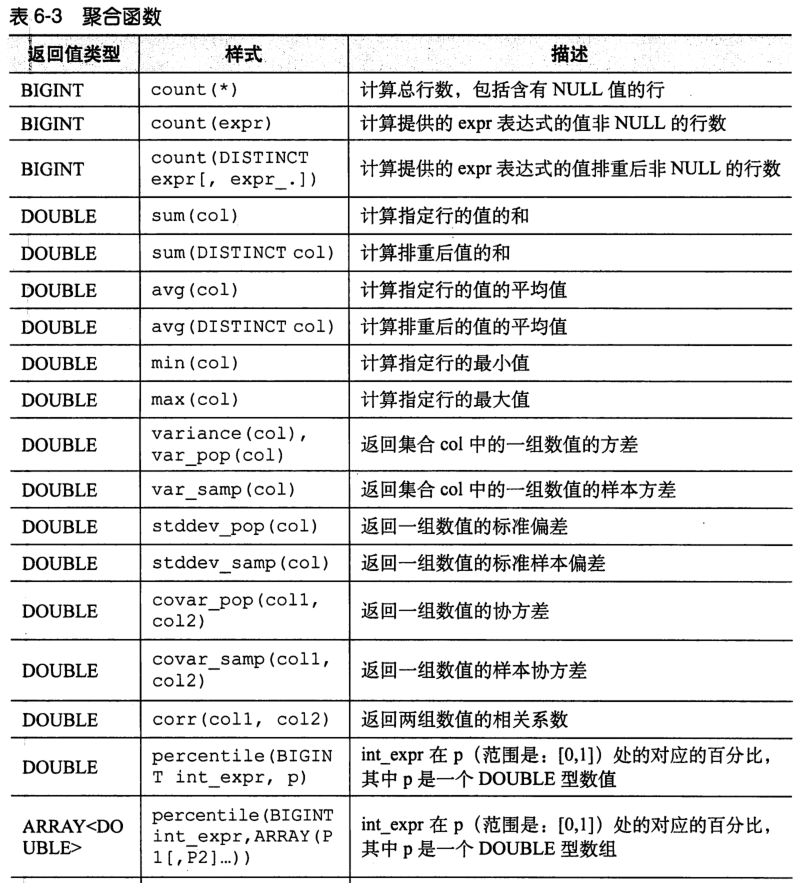

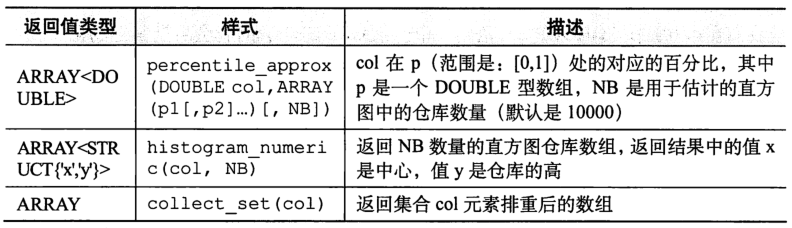
// 下边设置可以调高聚合的性能,这个设置会触发map阶段进行“顶级”聚合过秤,非顶级将会在执行一个GROUP BY后进行,不过这个设置会需要更多的内存。
hive> SET hive.map.aggr=true;
hive> SELECT count(*), avg(salary) FROM employees;
// 多个函数排重后的孤僻交易码个数
hive> SELECT count(DISTINCT symbol) FROM stocks;
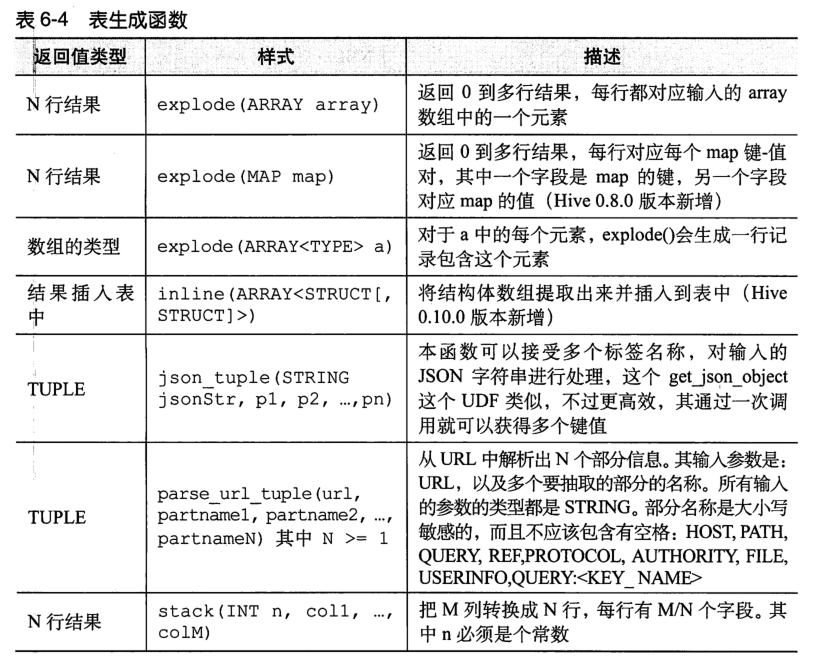
六、表生成函数
与聚合函数“相反的”一类函数就是表生成函数,其可以将单列扩展成多列或者多行。例如 AS 语句
例子:
SELECT parse_url_tuple(url, 'HOST', 'PATH', 'QUERY') AS (host, path, query) FROM url_table;
七、其他内置函数
有很多,关于时间的和关于字符串的。
八、LIMIT 句式
LIMIT子句勇于限制返回的行数。
// 下面只返回两行
hive> SELECT upper(name), salary, deductions["Federal Taxes"],
> round(salary * (1 - deductions["Federal Taxes"])) FROM employees
> LIMIT 2;
九、CASE ... WHEN ... THEN句式
和if条件语句类似,用于处理单个列的查询结果。
hive> SELECT name, salary,
> CASE
> WHEN salary < 50000.0 THEN 'low'
> WHEN salary >= 50000.0 AND salary < 70000.0 THEN 'middle'
> WHEN salary >= 70000.0 AND salary < 100000.0 THEN 'high'
> ELSE 'very high'
> END AS bracket FROM employees;
//返回结果
John Doe 100000.0 veryhigh
Mary Smith 80000.0 high
...
十、LIKE和RLIKE
RLIKE 是 Hive 功能的拓展,可以通过 Java 的正则表达式来指定匹配条件。
// LIKE
hive> SELECT name, address.street FROM employees WHERE address.street LIKE '%Ave.'
John Doe 1 Michigan Ave.
Todd Jones 200 Chicago Ave.
...
// RLIKE 后加正则表达式
//(参照Tony Stubbleine《正则表达式参考手册》、JanGoyvaerts和Tony Stubbleine(O' Reilly)所著的《正则表达式参考手册》)
// '.'表示和任意的字符匹配
// '*'表示重复“左边的字符串”零次到无数次
// '|'表示和x或者y匹配
hive> SELECT name, address.street
> FROM employees WHERE address.street RLIKE '.*(Chicago|Ontario).*';
Mary Smith 100 Ontario St.
Todd Jones 200 Chicago Ave.
十一、GROUP BY
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组执行聚合操作。
例如:
hive> SELECT year(ymd), avg(price_close) FROM stocks
>WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
>GROUP BY year(ymd);
1984 25.123142341341
1985 20.123145234131
...
// 有时候会用HAVING子句来补充条件查询
hive> SELECT year(ymd), avg(price_close) FROM stocks
>WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
>GROUP BY year(ymd);
>HAVING avg(price_close) > 50.0
// 等价于下边嵌套查询
hive> SELECT s2.year, s2.avg FROM
>(SELECT year(ymd) AS year, avg(price_close) AS avg FROM stocks)
>WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
>GROUP BY year(yml)) s2
>WHERE s2.avg > 50.0
1987 53.88923482352342
...