Hive数据类型和文件格式
大约 2 分钟
一、基本数据类型
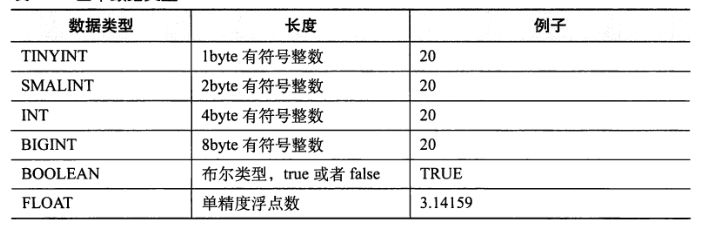
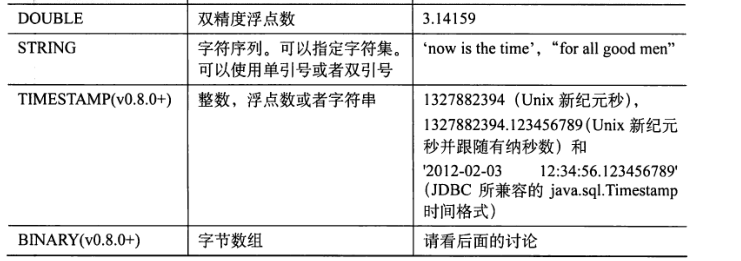
上面图列表了Hive所支持的基本数据类型。
相同:这些数据类型是对 JAVA 中接口的实现,例如STRING是java中的String
不同:
1、在其他SQL方言中,通常会提供限制最大长度的 “字符数组” ,但是Hive不支持。
因为 Hive 是为了优化磁盘的读和写的性能,列长度不重要(定长易于索引)
2、TIMESTAMP的值可以是整数(距离Unix新纪元时间1970年1月1日,午夜12点的秒数)
;也可以是浮点数,精确到纳秒(小数点后9位);还可以是字符号串,YYYY-MM-DD hh:mm:ss.fffffffff
3、TIMESTAMPS表示 UTC 时间。Hive 本身提供了不同时区相互转换的内置函数,to_utc_timestamp函数和 from_utc_timestamp函数
4、BINARY 和 VARCHAR 类似,但和 BLOB 不同。BINARY可以在记录中包含任意字节,这样可以防止Hive尝试将其作为数字,字符串等进行解析。
如果需要省略每行记录的尾部,无需使用 BINARY 数据类型。如果一个表的标结果指定的是3列,而实际数据文件每行记录包含有 5 个字段的话,那么 在 Hive 中最后 2 列数据将会被省略掉。
当 查询 将float与double对比,或者 int 和 float对比时,隐式使用较大的类型。
5、当需要把 字符串 转成 数值,那么需要显式:... cast(s AS INT) ... ;
二、集合数据类型
Hive 中的列支持使用 strut map 和 array 集合数据类型,如下图
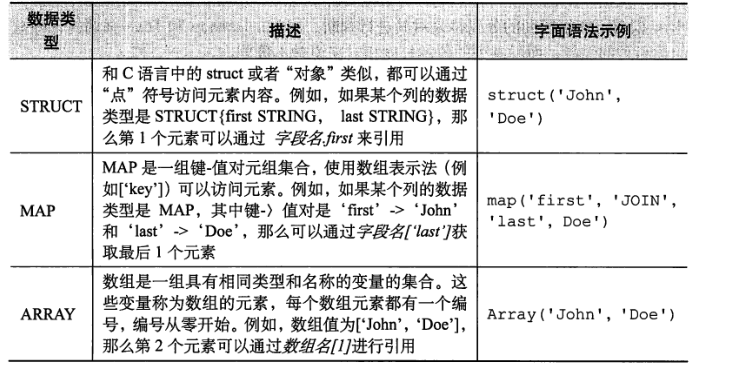
Hive 中没有 键 的概念,但是用户可以对表建立索引。
三、创建表的实例
人力资源的员工表
CREATE TABLE employees(
name STRTING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, STRING>;
adress STRUCT<street:STRING, city:STRING>, state:STRING, zip:INT)
);
四、文本文件数据编码
Hive中默认的记录和 字段分隔符
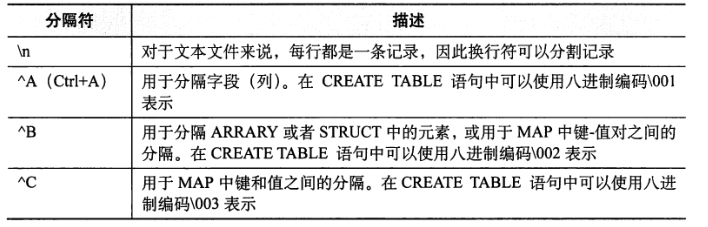
实例使用:
CREATE TABLE some_data(
first FLOAT,
second FLOAT,
third FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINQTED BY ',' ;
用例如使用 '\t' (也就是指标建) 作为字段分隔符。可以利用他处理CSV格式数据。