Spark相关概述
大约 1 分钟
一、Spark的核心组件是:
集群资源管理服务(Cluster Manager)
运行作业任务的节点(WorkerNode),
每个应用的任务控制节点 Driver 和 每个机器节点上有具有任务的执行进程(Executor)
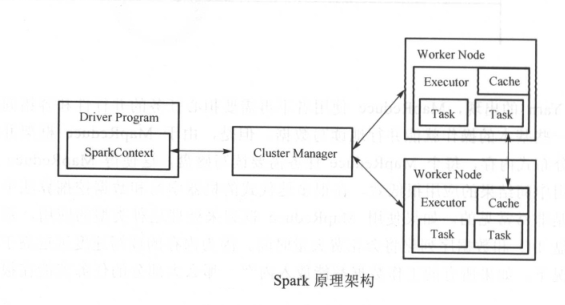
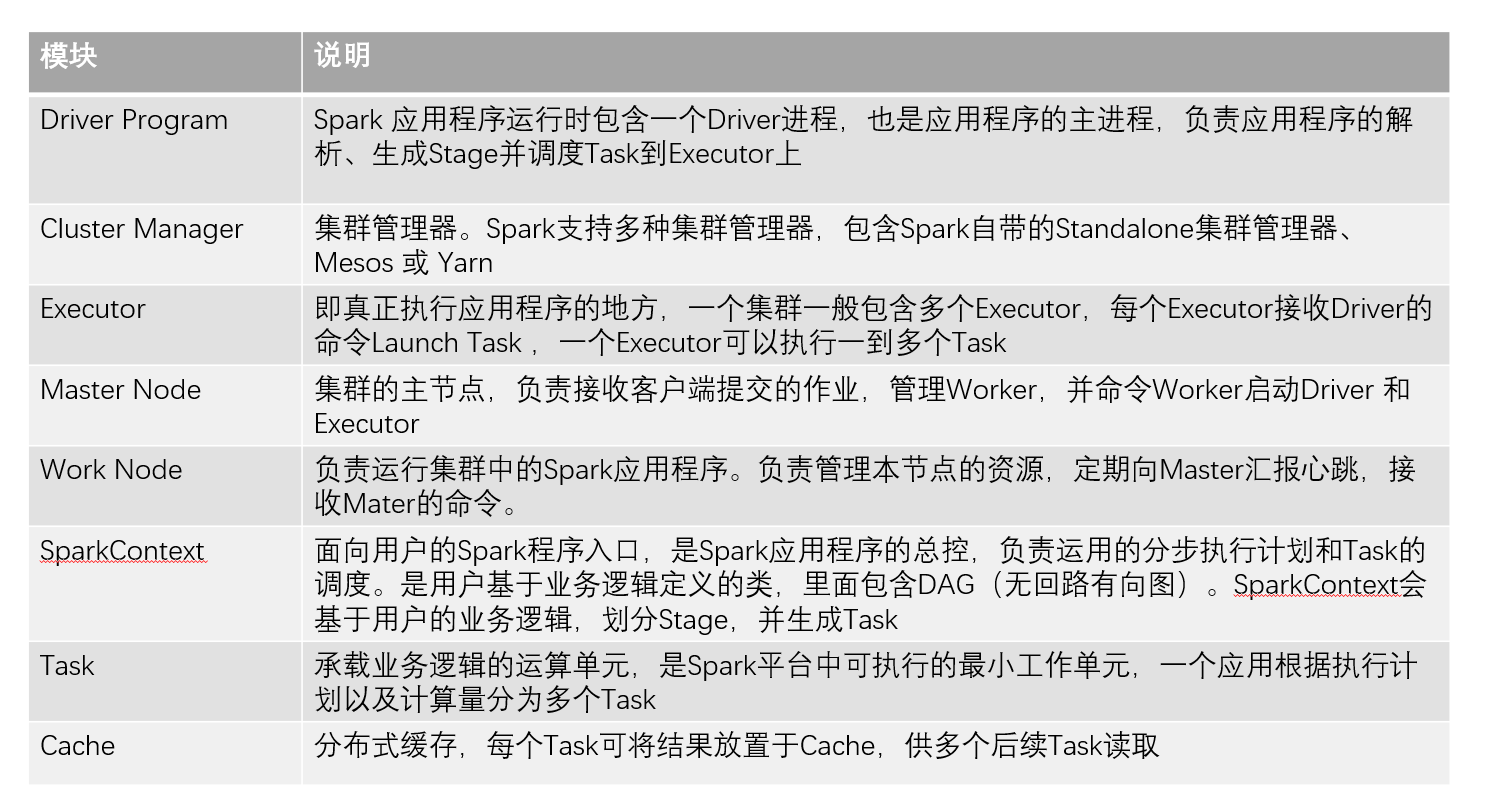
说明:
二、关键概念
(1)RDD
Spark 的核心概念是弹性分布式数据集。RDD 是一个只读且不可变的分布式对象集合,创建、转化即调用 RDD 操作者一系列过程贯穿于 Spark 大数据处理的始终。
(2)DAG
Spark使用有向无环图进行任务调度。
(3)Spark SQL
用于结构化数据的计算。
(4)DataFrame
分布式的、按照名名列的形式组织的数据集合。
(5)SQLContext
Spark SQL 提供 SQLContext 封装 Spark 中的所有关系型功能,可以用前面提到的SparkContext创建SQLContext。
(6)JDBC数据源
三、Spark 和 HDFS 的配合关系
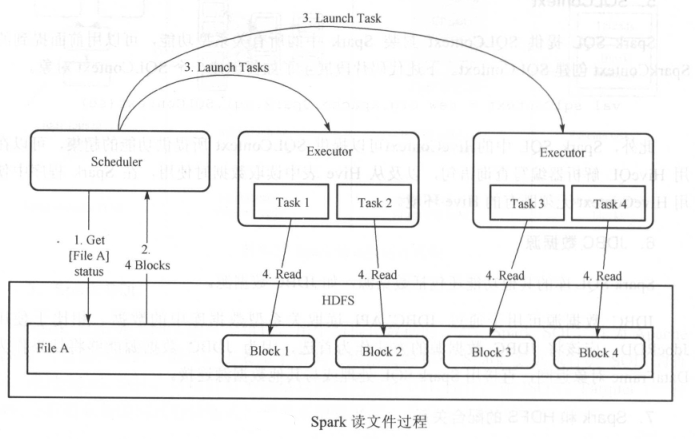
- (1)读取文件的详细步骤:
- SparkScheduler 与 HDFS 交互获取 File A 的文件信息。
- HDFS返回该文件具体的 Block 信息
- SparkScheduler 根据具体的 Block 数据量,决定一个并行度,创建多个 Task 去读取这些文件Block
- Executor 端执行 Task 并读取具体的 Block,作为 RDD(弹性分部数据集)的一部分
- (2)HDFS文件写入的详细步骤:
- SparkScheduler 创建要写入文件的目录
- 根据 RDD 分区分块情况,计算写出数据的 Task 数,并下发这些任务到 Executor
- Executor 执行这些 Task,将具体 RDD 的数据写入到第一步创建的目录下