伪共享
1、CPU缓存介绍
以近代CPU的视角来说,它们的作用都是作为CPU与主内存之间的高速数据缓冲区,L1最靠近CPU核心;L2其次;L3再次。
图具有3级缓存的处理器
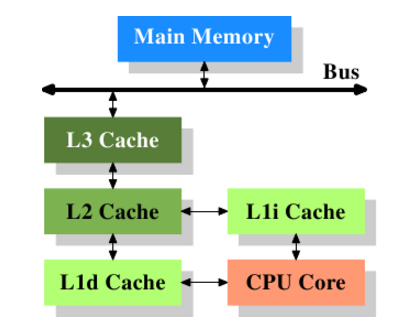
图片来自: https://lwn.net/Articles/252125/
早期,缓存设计过去常常在CPU外部安装L2和L3缓存,这会对延迟产生负面影响。
缓存设计总是在不断发展,特别是随着内存变得更便宜,更快,更密集。英特尔和AMD已经在缓存设计方面做了大量实验,
英特尔甚至尝试使用L4缓存。CPU市场正以前所未有的速度向前发展。
2、L1 L2 L3
L1(1级)高速缓存是计算机系统中存在的最快内存。在访问优先级方面,L1缓存具有CPU在完成特定任务时最可能需要的数据。L1缓存通常也有两种分割方式,分为指令缓存和数据缓存。指令高速缓存处理有关CPU必须执行的操作的信息,而数据高速缓存保存要在其上执行操作的数据。
L2(级别2)缓存比L1缓存慢,在大多数现代CPU中,L1和L2高速缓存存在于CPU内核本身,每个内核都有自己的高速缓存。
L3(Level 3)缓存是最大的缓存单元,也是最慢的缓存单元。它的范围在4MB到50MB之间。现代CPU在CPU裸片上有专用空间用于L3缓存,占用了大量空间。
3、缓存命中或错过和延迟
数据从RAM流到L3缓存,然后是L2,最后是L1。
当处理器正在寻找执行操作的数据时,它首先尝试在L1高速缓存中找到它。如果CPU能够找到它,则该条件称为缓存命中。
然后它继续在L2中找到它,然后在L3中找到它。
如果找不到数据,它会尝试从主存储器访问它。这称为缓存未命中。
4、缓存行(Cache Line)
缓存,是由缓存行组成的。一般一行缓存行有64字节
所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU存取缓存都是按照一行,为最小单位操作的。
5、伪共享的发生
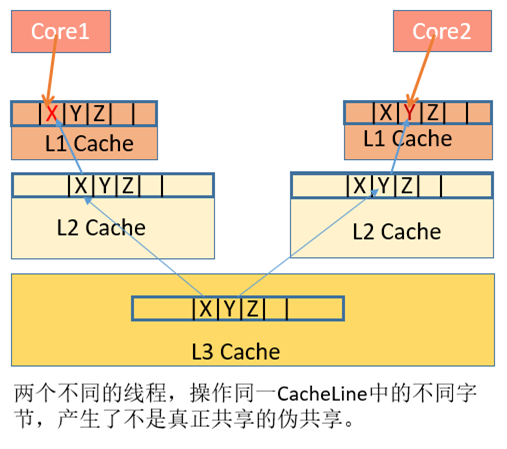
产生原因:
数据X、Y、Z被加载到同一Cache Line中,
线程A在Core1修改X,线程B在Core2上修改Y
根据MESI,假设是Core1是第一个发起操作的CPU核,Core1上的L1 Cache Line由S(共享)状态变成M(修改,脏数据)状态,然后告知其他的CPU核,图例则是Core2,引用同一地址的Cache Line已经无效了;
当Core2发起写操作时,首先导致Core1将X写回主存,Cache Line状态由M变为I(无效),而后才是Core2从主存重新读取该地址内容,Cache Line状态由I变成E(独占),最后进行修改Y操作, Cache Line从E变成M。可见多个线程操作在同一Cache Line上的不同数据,相互竞争同一Cache Line,导致线程彼此牵制影响,变成了串行程序,降低了并发性。
解决方法:
此时我们则需要将共享在多线程间的数据进行隔离,使他们不在同一个Cache Line上,从而提升多线程的性能。即 缓存行的填充。
图片来自:https://blog.csdn.net/qq_27680317/article/details/78486220
M 修改 (Modified) E 独享、互斥 (Exclusive) S 共享 (Shared) I 无效 (Invalid)
6、伪共享的实例
6.1、伪共享的产生
假如业务场景中,上述的类满足以下几个特点:
当value变量改变时,modifyTime肯定会改变createTime变量和key变量在创建后,就不会再变化。flag也经常会变化,不过与modifyTime和value变量毫无关联。
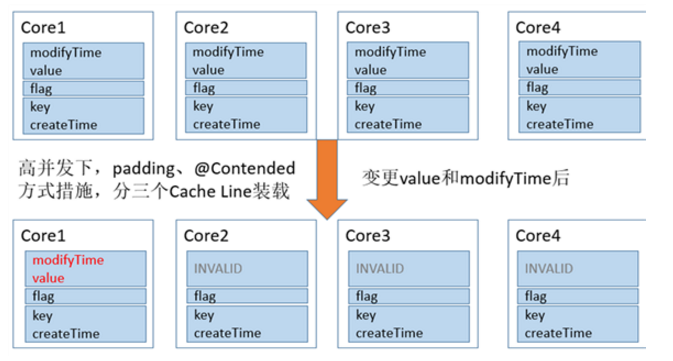
当上面的对象需要由多个线程同时的访问时,从Cache角度来说,就会有一些有趣的问题。当我们没有加任何措施时,Data对象所有的变量极有可能被加载在L1缓存的一行Cache Line中。
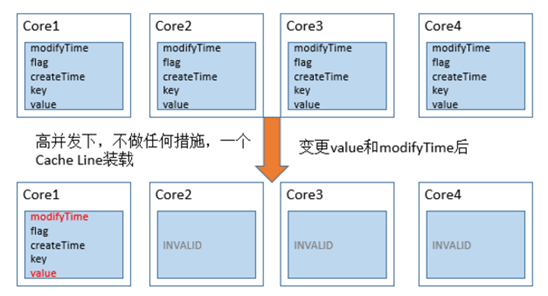
如图所示,每次value变更时,根据MESI协议,对象其他CPU上相关的Cache Line全部被设置为失效。其他的处理器想要访问未变化的数据(key 和 createTime)时,必须从内存中重新拉取数据,增大了数据访问的开销。

6.2、解决方法
(1)缓存行的填充
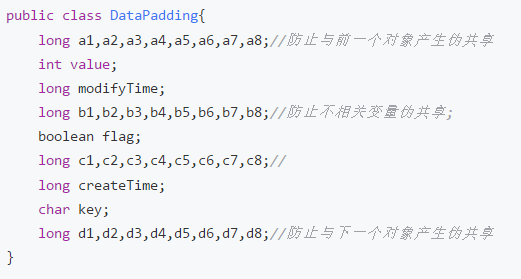
在JDK1.8以前,我们一般是在属性间增加长整型变量来分隔每一组属性。
通过填充变量,使不相关的变量分开。被操作的每一组属性占的字节数
加上前后填充属性所占的字节数,不小于一个cache line的字节数就可以达到要求
6.2、解决方法
(2)Contended注解方式
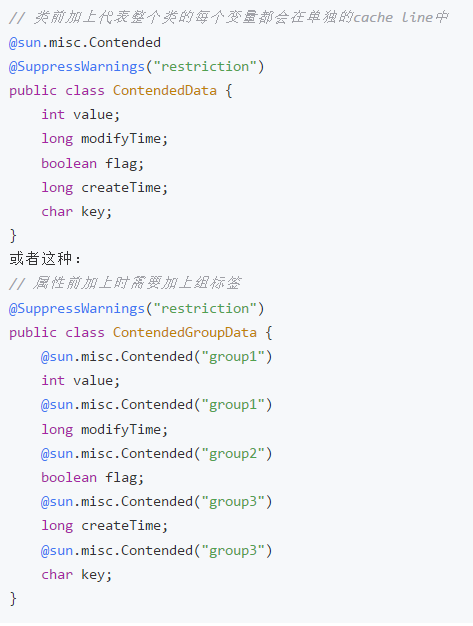
在JDK1.8中,新增了一种注解@sun.misc.Contended,来使各个变量在Cache line中分隔开。注意,jvm需要添加参数-XX:-RestrictContended才能开启此功能
采取上述措施图示:
更多实例:ConcurrentHashMap、Thread 、Disruptor