理解IO阻塞与非阻塞
大约 5 分钟
1、饭店吃饭的例子
A君喜欢下馆子吃饭,服务员点完餐后,A君一直坐在座位上等待厨师炒菜,什么事情也没有干,过了一会服务员端上饭菜后,A君就开吃了 -- 【阻塞I/O】
B君也喜欢下馆子,服务员点完餐后,B君看这个服务员长得不错便前去搭讪,一直和服务员聊人生理想,并时不时的打听自己的饭做好了没有,过了一会饭也做好了,B君也撩到了美女服务员的微信号 -- 【非阻塞I/O 】
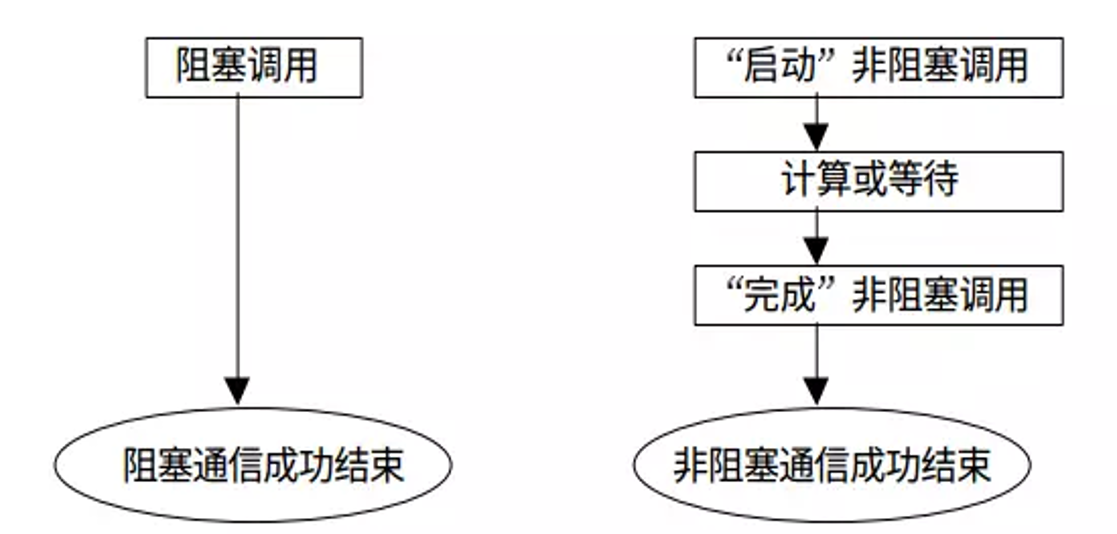
2、阻塞与非阻塞调用对比
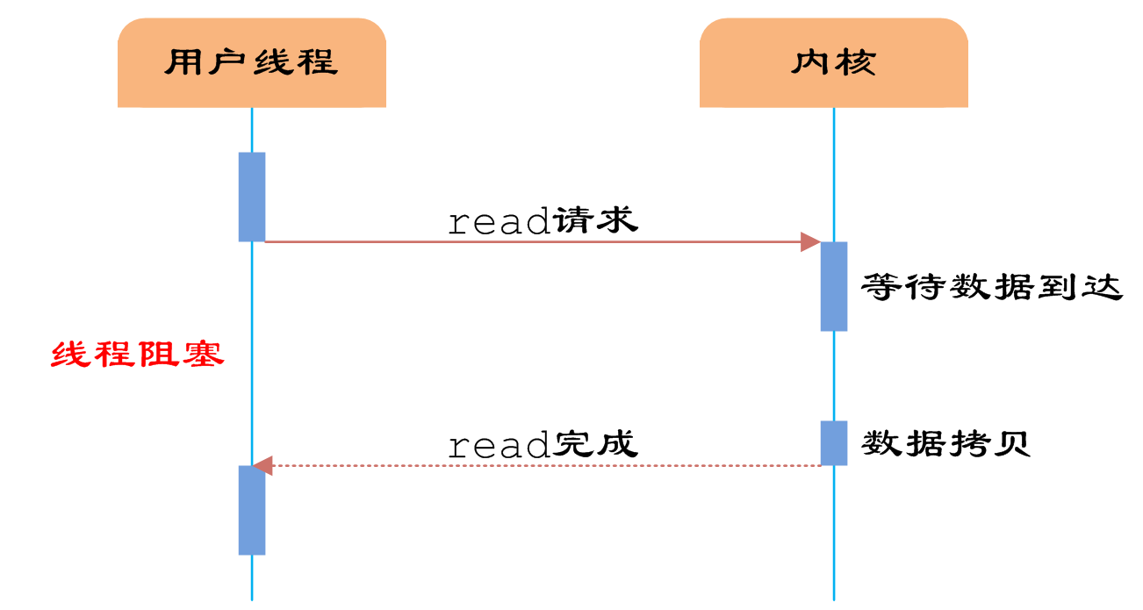
3、阻塞IO
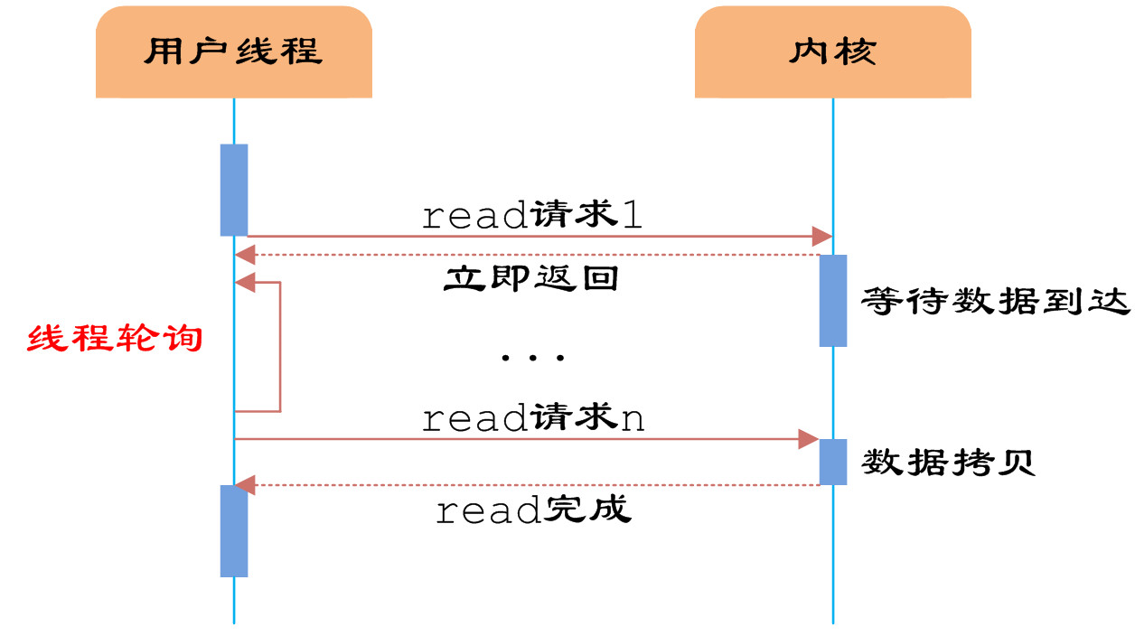
4、非阻塞IO
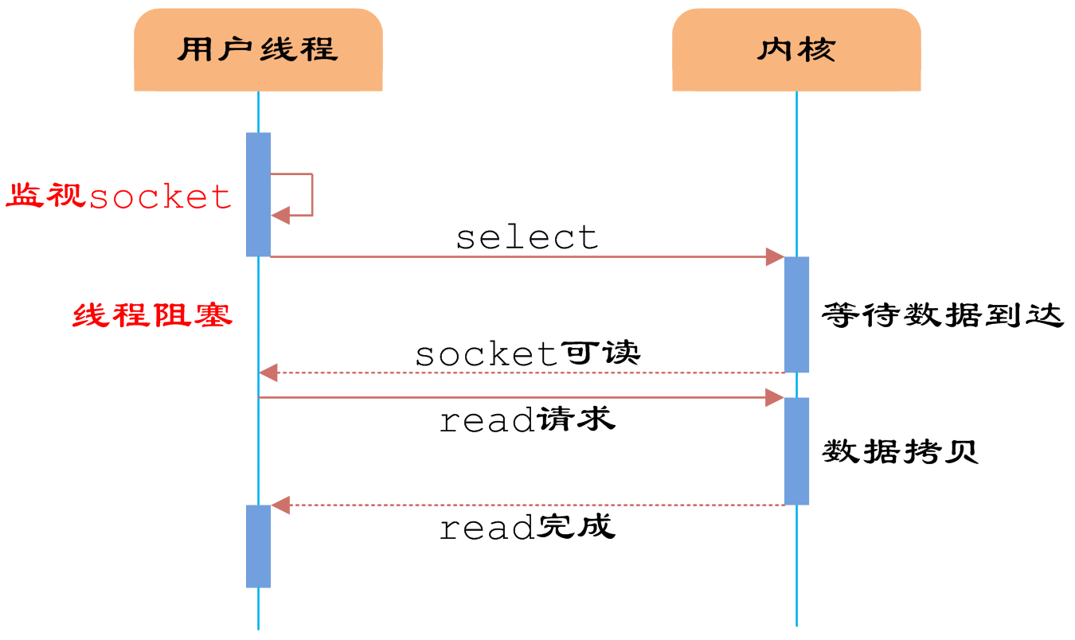
5、I/O复用模型
前面讲的非阻塞仍然需要进程不断的轮询重试。能不能实现当数据可读了以后给程序一个通知呢?所以这里引入了一个IO多路复用模型,I/O多路复用的本质是通过一种机制(系统内核缓冲I/O数据),让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。
常见的IO多路复用方式有【select、poll、epoll】,都是Linux API提供的IO复用方式
6、I/O复用select模型
7、select、epoll、poll模型对比
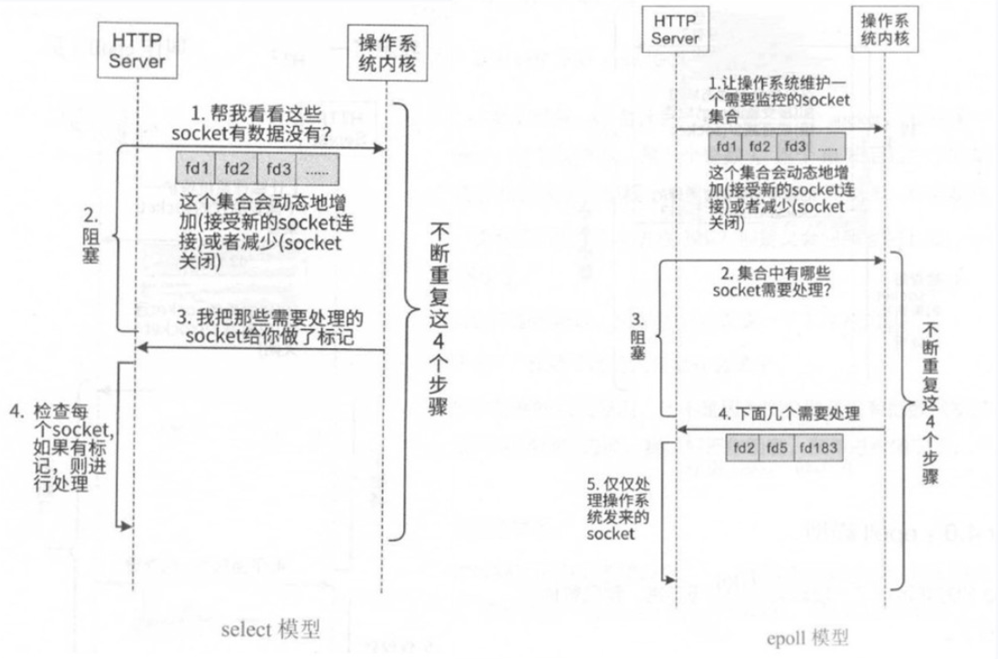
(1)select 时间复杂度O(n)
过程
(1)从用户空间拷贝fd_set到内核空间
(2)注册回调函数
(3)遍历所有fd,调用其对应的poll方法
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)把(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
总结
内核仅仅知道,有I/O事件发生了,却并不知道是哪几个I/O流。
我们只能无差别轮询所有的流,找出能读出数据(或写入数据的流),对他们进行操作。
处理的流越多,无差别遍历的事件就越长(O(n))
内核需要将消息传递到用户空间,都需要内核拷贝动作
(2)poll 时间复杂度O(n)
过程
while true
{
// 知道有一个流有I/O事件时,才往下执行
select(streams[])
for i in streams[]
{
if i has data
read until unavailable
}
}
总结
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,但是它没有最大连接数的限制,原因是它是基于链表来存储的。
内核需要将消息传递到用户空间,都需要内核拷贝动作
(3)epoll 时间复杂度O(1)
过程
{
active_stream[] = epoll_wait(epollfd)
for i in active_stream[]
{
read or write till
}
}
总结
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知用户线程,epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。
内核和用户空间共享一块内存来实现的
优点:
[1]、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)
[2]、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。
[3]、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
总结:
表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
8、多路复用的好处
select,poll,epoll都是IO多路复用的机制。
I/O多路复用可以通过把多个 I/O 的阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。
它的最大优势是系统开销小,并且不需要创建新的进程或者线程,降低了系统的资源开销
但是select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。