线程相关的知识
一、线程之间的通信机制
在命令式编程中:线程之间的通信机制有两种:共享内存和消息传递。
1)在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信。
2)在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显示进行通信。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。
简单例子:
全局变量A,方法B和C都对A进行操作,B和C就可以利用A进行通讯。
二、JMM (JAVA 内存模型)
JMM 的一个抽象概念,并不真实存在。
在JAVA中:
1)共享变量:所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享。
2)局部变量、方法定义参数和异常处理器参数不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
JMM决定一个线程和主内存的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
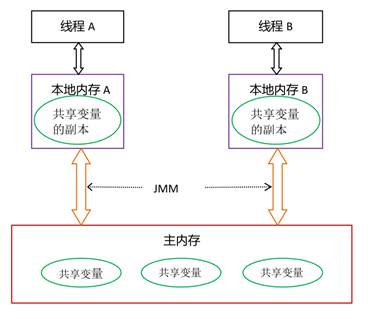
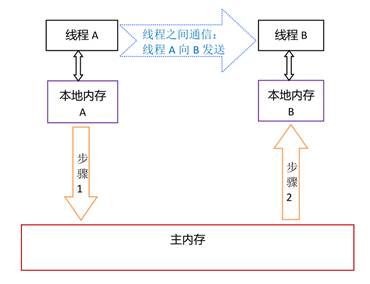
从上图来看,线程 A与线程 B 之间如要通信的话,必须要经历下面 2 个步骤:
首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去。
然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
三、重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
1) 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
综上,多个线程之间,执行的顺序是会随机改变的,需要我们注意。
四、顺序一致性模型
在顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在JMM 中,临界区内的代码可以重排序(但 JMM 不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。
五、总线事务
1)顺序一致性模型保证单线程内的操作会按程序的顺序执行,而 JMM 不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。这一点前面已经讲过了,这里就不再赘述。
2)顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而 JMM 不保证所有线程能看到一致的操作执行顺序。这一点前面也已经讲过,这里就不再赘述。
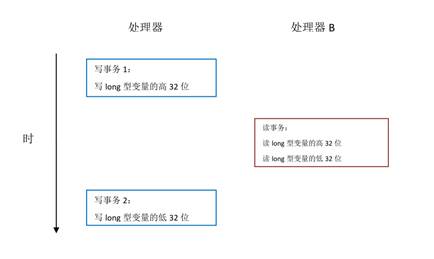
3) JMM 不保证对 64 位的 long 型和 double 型变量的读/写操作具有原子性,而顺序一致性模型保证对所有的内存读/写操作都具有原子性。
这个差异与处理器总线的工作机制密切相关。在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(bus transaction)。总线事务包括读事务(read transaction)和写事务(write transaction)。读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读/写内存中一个或多个物理上连续的字。这里的关键是,总线会同步试图并发使用总线的事务。在一个处理器执行总线事务期间,总线会禁止其它所有的处理器和 I/O 设备执行内存的读/写。下面让我们通过一个示意图来说明总线的工作机制:
在一些 32 位的处理器上,如果要求对 64 位数据的写操作具有原子性,会有比较大的开销。为了照顾这种处理器,java 语言规范鼓励但不强求 JVM 对 64 位的 long型变量和 double 型变量的写具有原子性。当 JVM 在这种处理器上运行时,会把一个 64 位 long/ double 型变量的写操作拆分为两个 32 位的写操作来执行。这两个 32 位的写操作可能会被分配到不同的总线事务中执行,此时对这个 64 位变量的写将不具有原子性。