用户行为特征提取
大约 5 分钟
一、场景
玩家每天游戏的各种操作(登录,充值等),这些行为都会记录到日志中,根据这些日志信息统计并分析用户行为。
(1)、时延
由于 Hadoop MapReduce 底层设计因素,在进行计算的过程中,在 Map 阶段的处理结果会写入磁盘中,在 Reduce 阶段再去下载 Map 阶段处理完的结果,Reduce 计算完毕后的结果又会回写磁盘中。
这样反复操作磁盘,I/O 开销很大,所耗费的时间自然也就偏高。这就意味着,Hadoop MapReduce 计算模型适合处理 批处理任务,而对实时统计任务则不适合,如 股票交易系统,银行交易系统。
(2)、吞吐量
在 Map 阶段中,被访问的数据是不能被修改的,直到整个作业 Job 完成。这就意味着,Hadoop MapReduce 是一个面向批处理的计算模型。
(3)、应用:
适合离线计算,MapReduce 支持统计用户点击量(PV)、独立访问量(UV)及大数据及的信息检索等。
二、整体流程
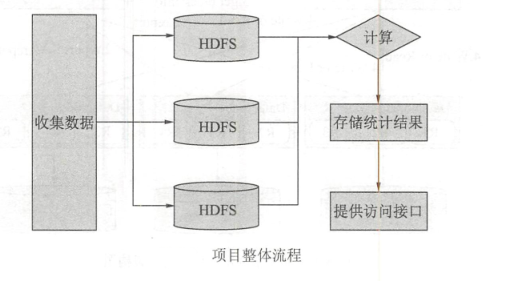
a. 收集数据
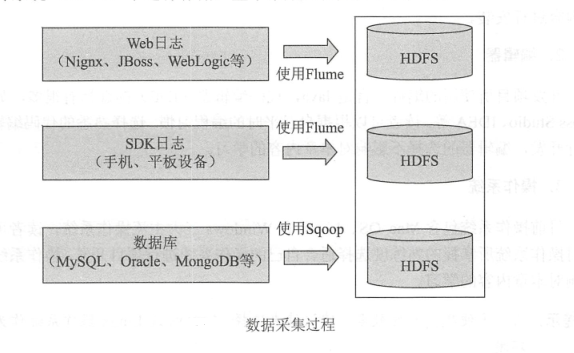
b. 采用HDFS将收集的数据按照业务进行分类存储
c. 使用计算模型进行分析、计算(模型有 Spark 、 Hive 、 Pig、 Tez 、 Flink等)
三、整体分析
(1)统计结果
针对运营:了解用户对哪些业务感兴趣,需求量比较大,就可以重点投入。
针对开发者:统计数据后的结果
(2)分析项目的目的
a、可以分析各个业务模块的活跃度、在各个模块停留的时间及用户的消费明细。
b、企业制定决策,需要实际数据作为支撑,用户行为结果能够帮助企业在某块业务进行决策时提供可靠的数据依据。
c、推送活动信息能不能造成反感。可以通过精准推送来提升用户的留存感,如用户在浏览某商品高,可推荐该商品的优惠活动。
四、行为分析
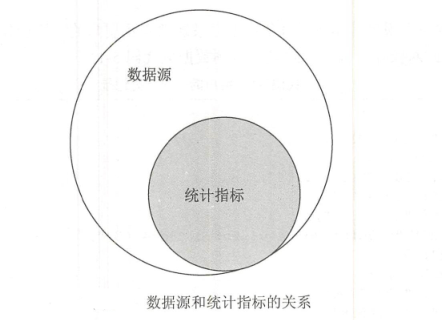
从业务数据中有效的分析各类统计指标(KPI)和数据源,让读者能够将**数据源**和**各类统计指标(KPI)**合理地关联起来。
(1)数据源 与 统计指标(KPI)分析
指标,这是很重要的;
合理的制定和可配置的制定可以更加方便后续工作。
每条日志记录通常表示:用户的一次行为记录。这些记录以 JSON 数据格式对操作行为进行封装。

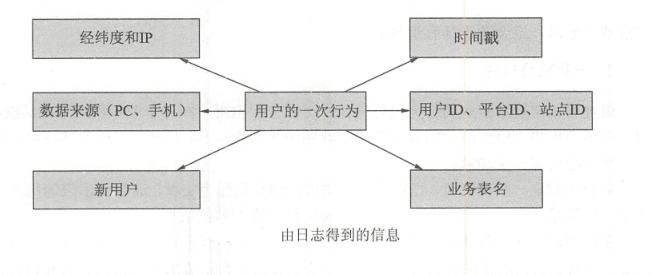
(2)数据源 与 统计指标(KPI)的关系
四、整体设计
(1)流程设计
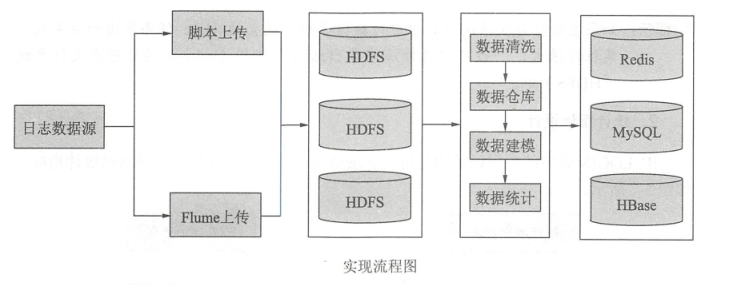
解释:
a. 数据量小,简单 使用脚本,反之用Flume等收集集群
b. 原始数据不一定是有效数据,所以要数据清洗,然后在用Hive进行数据建模
c. 实时计算可以用Flink、Spark、Storm
d. 最后结果可以存储在Oracle、Mysql、HBase、或者HDFS
(2)统计指标设计
a. 用户一周内登陆总数:根据用户ID去重来统计一周内登陆总数
// 用户 ID 去重,全平台,全站点统计
SELECT COUNT(DISTINCT ‘uid’) FROM ip_login WHERE tm BETWEEN 2019-12-23 AND 2019-12-29;
b. 用户一周中登陆分布情况,根据 IP 分组统计一周内的用户登录分布情况
// 用户 ID 去重且根据 IP 字段分组,全平台,全站点统计
SELECT ‘ip’, COUNT(DISTINCT 'uid') FROM ip_login WHERE tm BETWEEN 2019-12-23 AND 2019-12-29 GROUP BY 'uid','ip';
c. 不同平台下一周用户的登录情况,根据平台分组统计一周内的用户登录情况
// 用户 ID 去重且根据 plat 字段分组,全站点统计
SELECT 'plat', COUNT(DISTINCT 'uid') FROM ip_login WHERE tm BETWEEN 2019-12-23 AND 2019-12-29 GROUP BY 'uid', 'palt';
d. 不同站点下一周用户的登录情况,根据不同站点统计一周内用户的登录情况
// 用户 ID 去重且根据 bpid 字段分组,全平台统计
SELECT ‘bpid’, COUNT(DISTINCT 'uid') FROM ip_login WHERE tm BETWEEN 2019-12-23 AND 2019-12-29 GROUP BY 'uid', 'plat';
e. 用户一周内 PC 端和移动端登录情况:根据 PC 字段和移动端字段值来统计一周内用户登录情况
// 使用CASE WHEN 条件语句统计多指标任务
SELECT COUNT(CASE WHEN ‘ispc’ = 0 THEN 1 END), COUNT(CASE WHEN 'ismobile' = 1 THEN 1 END) FROM ip_login WHERE tm BETWEEN 2019-12-23 AND 2019-12-29;
f. 用户一周内每天的登录总数:按照天分组来统计每天用户登录总数
// 按照分区时间分组,用户 ID 去重进行全平台、全站点统计
SELECT tm, COUNT(DISTINCT 'uid') FROM ip_login WHERE tm BETWEEN 2019-12-23 AND 2019-12-29 GROUP 'uid', tm;
注意:在编写Hive SQL进行指标统计进行去重
小数量使用 COUNT DISTINCT
数据量大推荐使用 GROUP BY 去重,避免数据倾斜(?) 数据倾斜无非就是大量的相同key被partition分配到一个分区里,造成了'一个人累死,其他人闲死'的情况:https://blog.csdn.net/weixin_35353187/article/details/84303518
此篇文章为《Hadoop大数据挖掘入门到放弃》笔记!