kafka架构设计
1、应用场景
同时为发布和订阅提供高吞吐量、消息持久化、分布式功能、支持数据并行加载到Hadoop中
实际:
1、发布系统通知:如评论、点赞、关注这些事件发生后,可以把这些操作放入到kafka消息队列中,如果用户量一大直接操作数据库,服务器压力顶不住。所以把这些通知先存入kafka中,然后一个个消费掉。
2、一些项目数据同步问题也可以用到。
3、监测数据:分布式应用程序生成的统计数据集中聚合。
4、分布式:假设有系统B、C、D都需要系统A的数据
5、事件采集:其中状态的变化根据时间的顺序记录下来,kafka支持这种非常大的存储日志数据的场景。
如:日志收集、消息系统、活动追踪、运营指标、流式处理、热点点赞、评论、关注、发短信。
2、架构设计
kafka流程及概念:
(1)kafka中的主题(Topic)
当大家听到京广高速的时候,知道这是一条从北京到广州的高速路,这个是逻辑上的叫法,可以理解成kafka种的Topic。
(2)kafka中的分区(Partition)
一条高速路通常会有对各车道进行分流,每个车道上的车都是通往一个目的地的(属于同一个Topic),这里所说的车道便是Partition。
如下图:其中分区路由可以简单理解成一个Hash函数,生产者在发送消息时,完全可以自定义这个函数来决定分区规则。如果分区规则设定合理,所有消息将均匀地分配到不同的分区中。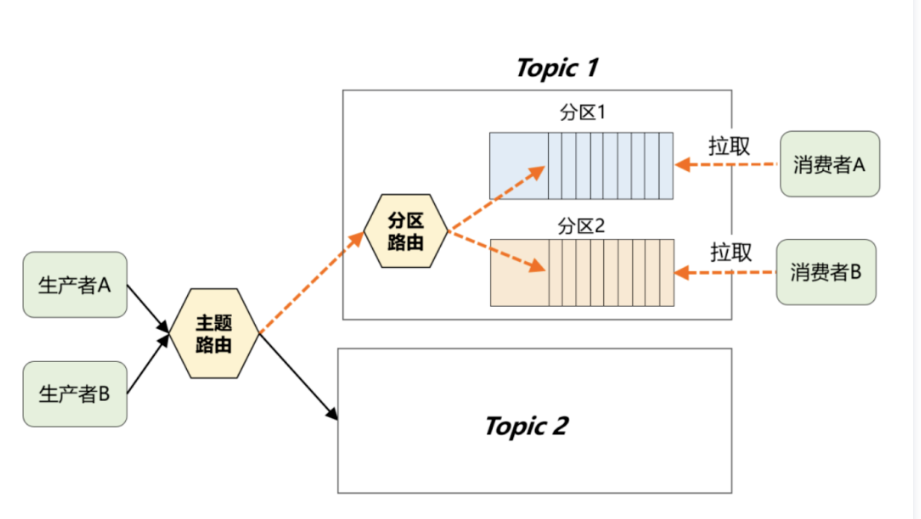
通过Topic逻辑分类与Partition物理分片,最终多个Partition均匀地分布在集群中的每台机器上,从而很好地解决了存储的扩展性问题。
(3)kafka中的消费组
诉求:
1、消费端需要与partition结合并进行并行处理。
2、广播消费能力: 同一个Topic可以被多个消费者订阅,一条消息能够被消费多次。
3、集群消费能力: 当消费者本身也是集群时,每一条消息只能分发给集群中的一个消费者进行处理。
为了满足以上诉求。Kafka引出消费组的概念,每个消费者都有一个对应的消费组,组间进行广播消费,组内进行集群消费。此外,kafka还限定了: 每个partition只能由消费组中的一个消费者进行消费。
如下图: 假设主题A共有4个分区,消费组2只有两个消费者,最终这两个消费组将平分整个负载,各自消费两个分区的消息。
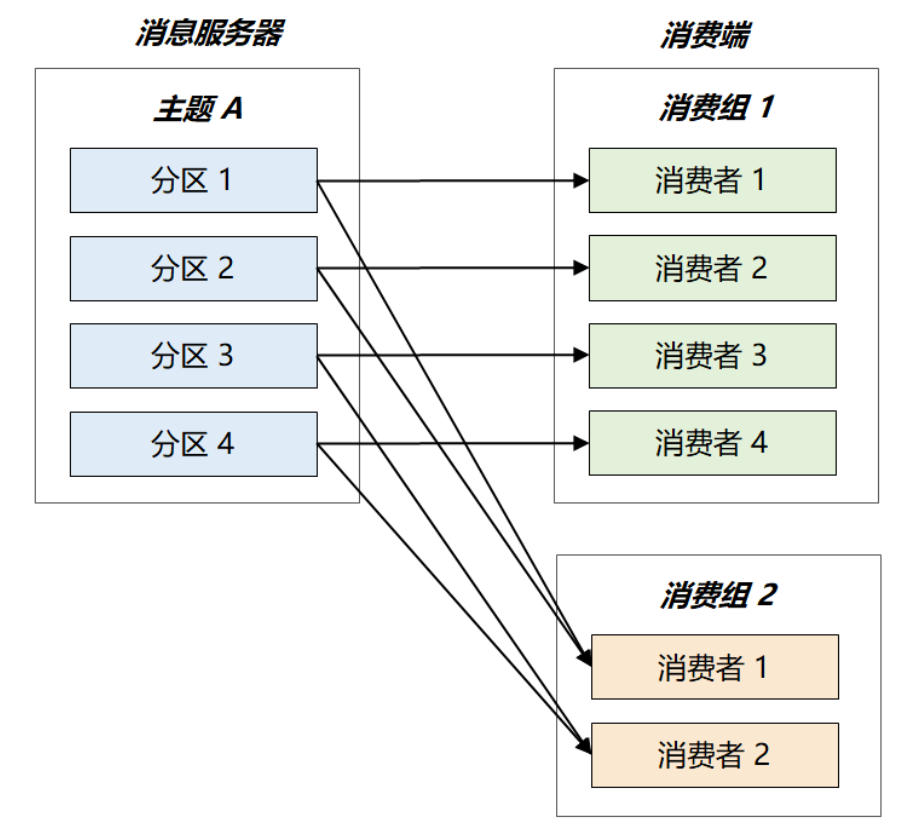
若要加快消息处理速度,向消费组2中增加新的消费者即可,kafka将以Partition为单位重新做负载均衡。当增加到4个消费者时,每个消费者仅需处理1个partition,处理速度将提升两倍。
(4)kafka怎么保证高可用
1、消息持久化存储,机器重启后历史数据不被丢失
2、多副本冗余机制,在kafka集群中,每个partition都有多个副本,同一分区的不同副本中保存的是相同的消息。
3、一主多从,其中leader副本负责读写请求。follower副本只负责和leader副本同步消息,当leader副本发生故障时,他才有机会被选举成新的leader副本并对外提供服务,否则一直是待命状态。
现在,假设kafka集群中有4台服务器,主题A和主题B都有两个Partition,且每个Partition各有两个副本,那最终的多副本架构将如下图所示: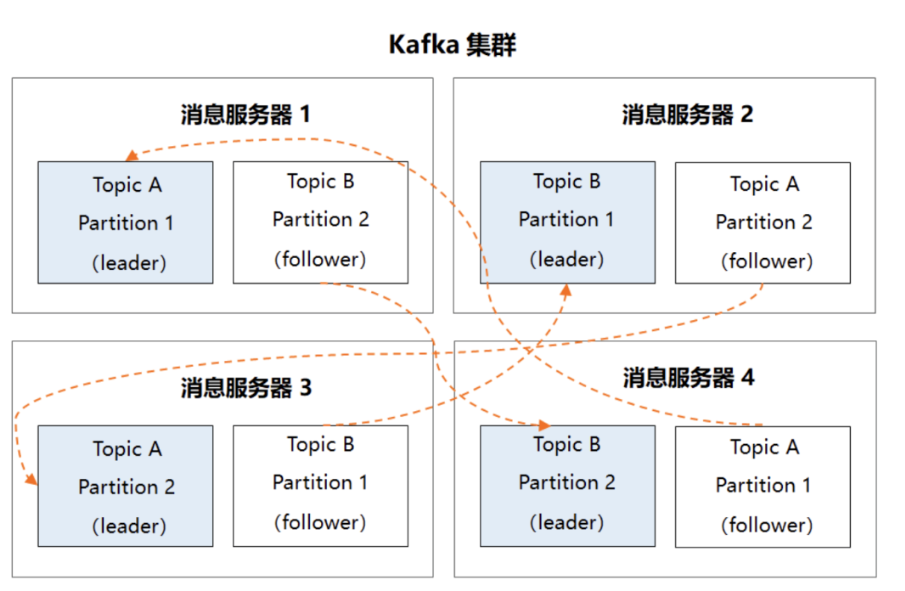
很显然,这个集群中任何一台机器宕机,都不会影响kafka的可用性,数据仍然是完整的。
(5)kafka整体架构
如图: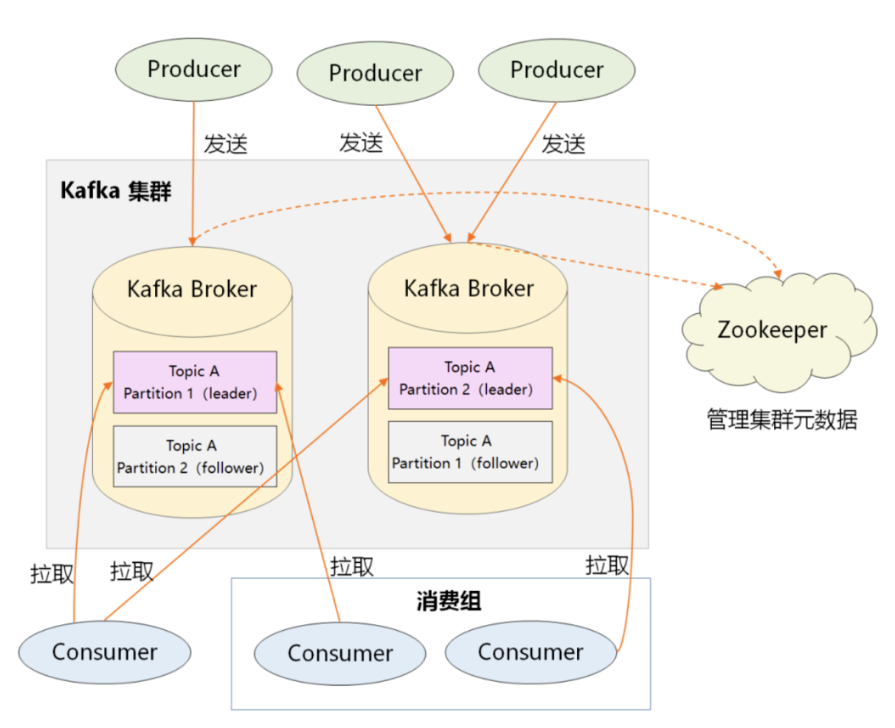
1、producer:生产者,负责创建消息,然后投递到kafka集群中,投递时需要指定消息所属的topic,同时确定好发往哪个partition。
2、consumer:消费者,会根据它所订阅的topic以及所属的消费组,决定从哪些partition中拉去消息。
3、broker:消费服务器,可水平拓展,负责分区管理、消息持久化、故障自动转移等。
4、zookeeper:负责集群的元数据管理的功能,如果集群中有哪些broker节点以及topic,每个topic又有哪些partition等。
5、很显然,在kafka整体架构中,partition是发送消息、存储消息、消费消息的纽带。
3、kafka性能优势
1、顺序写
Kafka 用的是顺序写,追加数据是追加到末尾,磁盘顺序写的性能极高,在磁盘个数一定,转数达到一定的情况下,基本和内存速度一致。随机写的话是在文件的某个位置修改数据,性能会较低。
2、零拷贝
可以看到数据的拷贝从内存拷贝到 Kafka 服务进程那块,又拷贝到 Socket 缓存那块,整个过程耗费的时间比较高。Kafka 利用了 Linux 的 sendFile 技术(NIO),省去了进程切换和一次数据拷贝,让性能变得更好。
3、日志分段存储
Kafka 规定了一个分区内的 .log 文件最大为 1G,做这个限制目的是为了方便把 .log 加载到内存去操作:
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个 9936472 之类的数字,就是代表了这个日志段文件里包含的起始 Offset,也就说明这个分区里至少都写入了接近 1000 万条数据了。
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是 1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
如果大家有了解 HDFS 就会发现 NameNode 的 edits log 也会做出限制,所以这些框架都是会考虑到这些问题。
4、kafka网络设计
1、Acceptor接收客户端发来的请求
2、轮询分发给Processor线程处理
3、Processor将请求封装成Request对象,放到RequestQueue队列
4、KafkaRequestHandlerPool分配工作线程,处理RequestQueue中的请求
5、KafkaRequestHandler线程处理完请求后,将响应Response返回给Processor线程
6、Processor线程将响应返回给客户端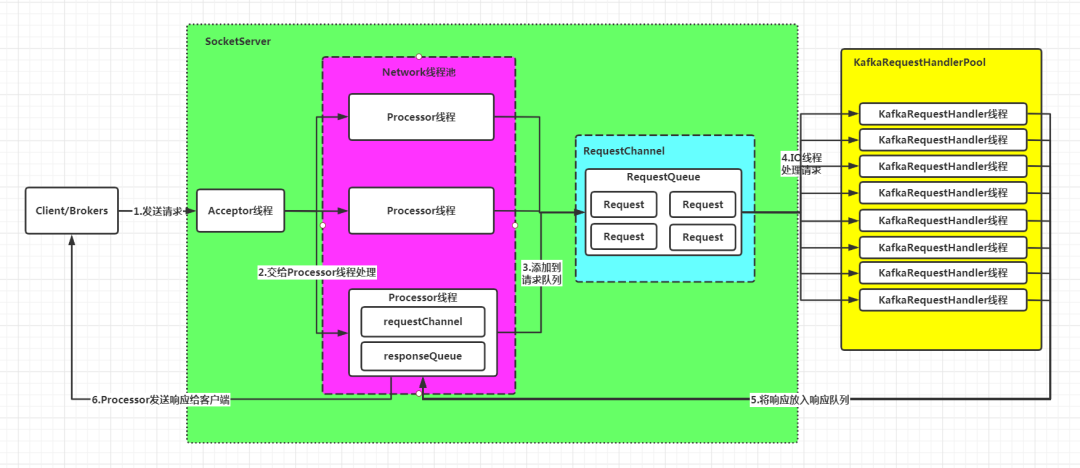
从图中可以看出,SocketServer和KafkaRequestHandlerPool是其中最重要的两个组件:
1、SocketServer:实现Reactor模式,用于处理多个Client(包括客户端和其他broker节点)的并发请求,并将处理结果返给Client
2、KafkaRequestHandlerPool:Reactor模式中的Worker线程池,里面定义了多个工作线程,用于处理实际的I/O请求逻辑。
参照:https://www.modb.pro/db/131830
5、kafka简单使用步骤
(1)引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
(2)修改application.yml
spring:
application:
name: springboot-kafka
kafka:
bootstrap-servers: 10.5.13.230:9092 # 指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失
retries: 0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: all # 可以设置的值为:all, -1, 0, 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1s
group-id: order
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 设置并发数
concurrency: 3
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
(3)增加Constant.java
package com.example.constant;
public class Constant {
/**
* topic
*/
public static final String TOPIC_TEST1 = "topic_test1";
/**
* group
*/
public static final String TOPIC_GROUP1 = "topic_group1";
}
(4)增加生产者MessageServiceKafkaImpl.java和MessageService.java
package com.example.service;
public interface MessageService {
void sendMessage(String id);
}
package com.example.service.impl;
import com.example.constant.Constant;
import com.example.service.MessageService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Service
public class MessageServiceKafkaImpl implements MessageService {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@Override
public void sendMessage(String id) {
System.out.println("待发送短信的订单已纳入处理队列(kafka),id:" + id);
// 发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(Constant.TOPIC_TEST1, id);
// 监听消息加入队列结果返回
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
System.out.println("生产者发送成功(kafka),id:" + id);
}
@Override
public void onFailure(Throwable throwable) {
System.out.println("生产者发送失败(kafka),id:" + id);
}
});
// kafkaTemplate.send("zheng", id);
}
}
(5)增加消费者MessageListener.java
package com.example.consumer;
import com.example.constant.Constant;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
public class MessageListener {
@KafkaListener(topics = {Constant.TOPIC_TEST1}, groupId = Constant.TOPIC_GROUP1)
public void onMessage(ConsumerRecord<?, ?> record, Acknowledgment ack,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
System.out.println("已完成短信发送业务(kafka),id:" + msg);
ack.acknowledge();
}
}
}
(6)增加测试类SendMessageTest.java
package com.example.init;
import com.example.service.MessageService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.UUID;
@Service
public class SendMessageTest {
@Autowired
private MessageService messageService;
@PostConstruct
public void send() {
for (int i = 0; i < 100; i++) {
messageService.sendMessage(UUID.randomUUID().toString());
}
}
}