一、介绍
Milvus 创建于 2019 年,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习 (ML) 模型生成的大量嵌入向量。
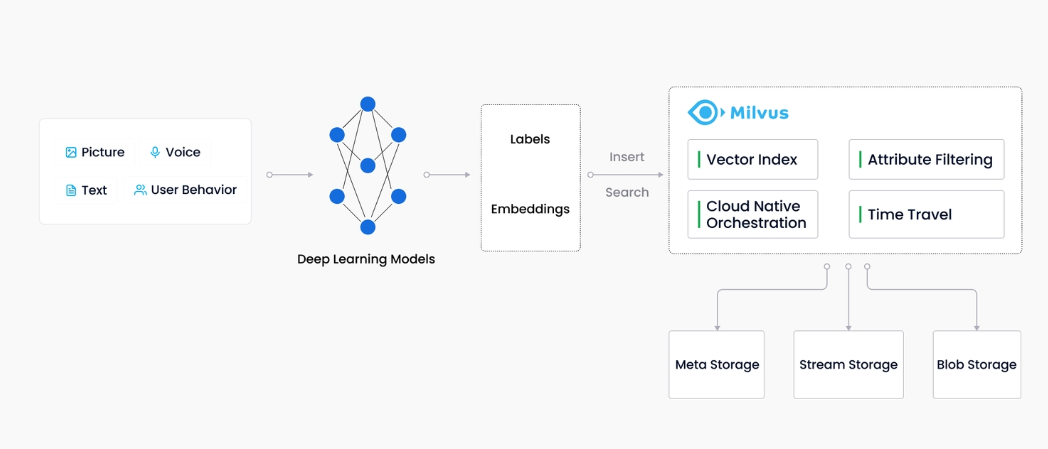
作为专门设计用于处理对输入向量的查询的数据库,它能够以万亿级对向量进行索引。与现有关系数据库主要按照预定义模式处理结构化数据不同,Milvus 是自下而上设计的,用于处理从非结构化数据转换的嵌入向量。
随着互联网的发展和发展,非结构化数据变得越来越普遍,包括电子邮件、论文、物联网传感器数据、Facebook 照片、蛋白质结构等等。为了使计算机理解和处理非结构化数据,使用嵌入技术将这些数据转换为向量。Milvus 存储并索引这些向量。Milvus 能够通过计算两个向量的相似距离来分析它们之间的相关性。如果两个嵌入向量非常相似,则意味着原始数据源也相似。
来源:
https://milvus.io/docs/v2.1.x/overview.md
大约 7 分钟