1、建立三个文档
小于 1 分钟
a.创建学生成绩表,结果如下。
Rowkey:id
列族:info和course,course包括3个版本数据
b.插入数据
数据包括
| 学生学号 | Info | course | |||||
|---|---|---|---|---|---|---|---|
| name | age | sex | address | Chinese | math | english | |
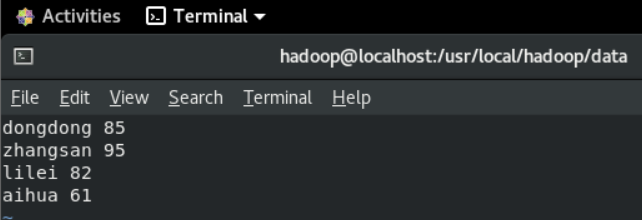
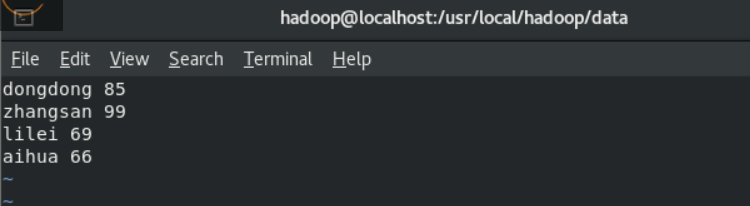
| 95001 | Jom | 20 | 男 | 山东省济南市 | 80 | 85 | 89 |
| 95002 | Tom | 19 | 男 | 山东省济南市 | 55,60 | 80 | 71 |
| 95003 | Lily | 20 | 女 | 北京市 | 65 |
命令:hdfs dfs -mkdir -p /usr/local/hadoop/data/txtdir
截图: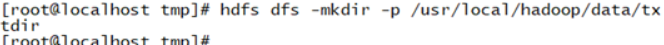
本地创建文件a.txt,b.txt,c.txt上传到HDFS /usr/local/hadoop/data/txtdir
命令:echo “I am student” > a.txt
以下为springboot整合elasticsearch
es版本为7.2.1
<!-- ES -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.2.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.2.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client-sniffer</artifactId>
<version>7.2.1</version>
</dependency>
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
Elasticsearch 是一款功能强大的分布式搜索引擎,支持近实时的存储、搜索数据。
Elasticsearch和磁盘之间是文件系统缓存,在内存索引缓冲区中的文档 会被写入到一个新的段中 ,但是这里新段会被先写入到文件系统缓存,这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
查看逻辑,更多用 EXPLAIN EXTENDED
表足够小用map-side JOIN
对于小数据集,单机或单线程执行时间比较短
hive> set oldjobtracker=${hiveconf.mapred.job.tracker};
hive> set mapred.job.tracker=local;
hive> set mapred.tmp.dir=/home/edward/tmp
hive> SELECT * from people WHERE firstname=bob;
hive> set mapred.job.tracker=${oldjobtracker};
Hive 中分区的功能是非常有用的。因为通常要对输入进行全盘扫描,来满足查询条件。
如:存储日志,log_2020_01_01、log_2020_01_02等
hive> CREATE TABLE
hive> CREATE TABLE log_2020_01_01 (id int, part string, quantity int);
hive> CREATE TABLE log_2020_01_02 (id int, part string, quantity int);
hive> CREATE TABLE log_2020_01_04 (id int, part string, quantity int);
hive> SELECT part,quantity log_2020_01_01
> UNION ALL
> SELECT part,quantity from log_2020_01_04
> WHERE quantity < 4;
Hive没有键的概念,可以对一些字段建立索引来加速某些操作,一张表的索引储存在另外一张表中。EXPLAIN命令可以查看某个查询语句是否用到了索引。
// 定义表
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
PARTITIONED BY (country STRING, state STRING); // 分区:hdfs://xxx/2020/02/20/xx
// 建立索引,仅对字段country建立索引
CREATE INDEX employees_index
ON TABLE employees(country)
// AS ... 指定索引处理器
AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
WITH DEFERRED REBUILD
IDXPROPERTIES('creator' = 'me', 'created_at' = 'some_time')
IN TABLE employees_index_table
PARTITIONED BY (country, name)
COMMENT 'Employees indexed by country and name.'
视图可以允许保存一个查询(并)像对待表一样对这个查询进行操作。(这是一个逻辑结构,因为它不像一个表会存储数据。
当查询长且复杂,通过使用视图将这个查询语句分割成多个小的、更可控的片段可以降低这种复杂度。
例如:
改进前:Hive 查询语句中含有多层嵌套
FROM(
SELECT * FROM people JOIN cart ON (cart.people_id=people.id) WHERE firstname='john'
) a SELECT a.lastname WHERE a.id=3;
(1)cast() 函数,可以使用这个函数对指定的值进行显式的类型转换。
例如:
// 当salary字段的值是不合法的浮点数字符串的话,Hive会返回NULL
SELECT name, salary FROM employees WHERE cast(salary AS FLOAT) < 100000.0;