一、读文件
HDFS有一个文件系统实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件。
HDFS通过RPC调用NameNode获取文件块的位置信息,对于文件的每一个块,NameNode会返回该块副本DataNode的节点地址。
另外,客户端还会根据网络拓扑来确定它与每一个DataNode的位置信息,从离它最近的那个DataNode获取数据块的副本,最理想的情况是数据块就储存在客户端所在的节点上。
具体过程:
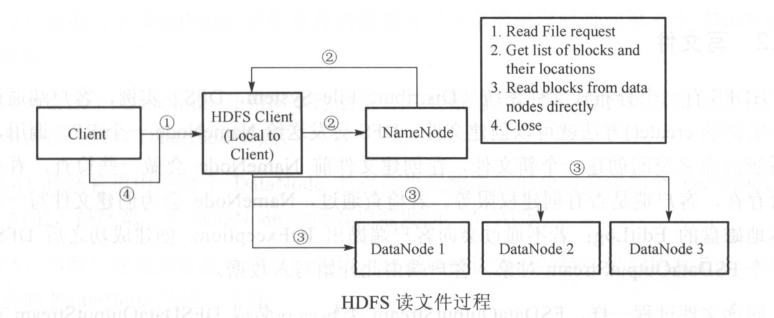
(1)客户端发起请求
(2)客户端与NameNode得到文件的块及位置信息列表
(3)客户端直接和DataNode交互读取数据
(4)读取完成关闭连接
这样设计的巧妙之处有:
(1)在运行MapReduce任务时,每个客户端就是一个DataNode节点。
(2)NameNode 仅需要相应块的位置信息请求,否则随着客户端的增加,NameNode会很快成为瓶颈。
Hadoop的网络拓扑。在海量数据处理过程中,主要限制因素时节点之间的带宽。衡量两个节点之间的带宽往往很难实现,在这里Hadoop采取了一个简单的方法,它把网络拓扑看成一棵树,两个节点的距离等于他们到最近共同祖先距离的综合,而树的层次可以这么划分:
a、同一个节点中的进程
b、同一机架上的不同节点
c、同一数据中心不同机架
d、不同数据中心的节点
大约 4 分钟