分布式全局唯一ID生成策略
一、需求
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
当需要将节点之间在不同时间的交互做唯一标识,数据日渐增长,
对数据库的分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求。
此时一个能够生成全局唯一ID的系统是非常必要的。
二、ID生成的原则:
1、全局唯一性:不能出现重复的ID(最基本的要求)
2、高性能,低延迟。(不要太繁杂的算法)
3、易于存储,(占用较低的空间)
三、相对应的算法:
1、雪花算法 snowflake

1位标识:由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
41位时间戳:41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截 )得到的值,这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的。可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
10位机器标识码:可以部署在1024个节点(2^10=1024),如果机器分机房(IDC)部署,这10位可以由 5位机房ID + 5位机器ID 组成。(但是这个也是会重复的网上说法木有参考性,可以改为TPM安全芯片、网卡等的唯一标识码,原则上他们是全球唯一的)
12位序列:毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
(1)优点:
时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增。(排序方便,会有很多好处)
灵活度高,可以根据业务需求,调整bit位的划分
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的(多一个依赖的组件,多一个风险,并增加了系统的复杂性)
(2)缺点:
依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成。(网上有优化时钟回拨问题利用记录最后一次成ID的时间,也可利用zookeeper、redis中间件)
在分布式环境上,每个服务器的时钟不可能完全同步,有时会出现不是全局递增的情况。
应用举例:
Mongdb objectID
可以算作是和snowflake类似方法,通过“时间+机器码+pid+inc”共12个字节,通过4+3+2+3的方式最终标识成一个24长度的十六进制字符。
2、UUID
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符。(微软叫GUID:Globally Unique Identifier)
为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID的复杂特性在保证了其唯一性的同时,意味着只能由计算机生成。
(1)基于时间的UUID
基于时间的UUID通过计算当前时间戳、随机数和机器MAC地址得到。由于在算法中使用了MAC地址,这个版本的UUID可以保证在全球范围的唯一性。但与此同时,使用MAC地址会带来安全性问题(曾被用于寻找梅丽莎病毒的制作者位置)。如果应用只是在局域网中使用,也可以使用退化的算法,以IP地址来代替MAC地址--Java的UUID往往是这样实现的(当然也考虑了获取MAC的难度)。
(2)DCE安全的UUID
DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
(3)基于名字的UUID(MD5)
基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
(4) 随机UUID
根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但随机的东西就像是买彩票:你指望它发财是不可能的,但狗屎运通常会在不经意中到来。
(5) 基于名字的UUID(SHA1)
和版本3的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
(1) 优点:
性能非常高:本地生成,没有网络消耗。
(2) 缺点:
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用(mysql主键索引是B+树,推荐使用自增存储效率高)
3、利用数据库
步长需设置为N,每台的初始值依次为0,1,2…N-1那么整个架构就变成了如下图所示:
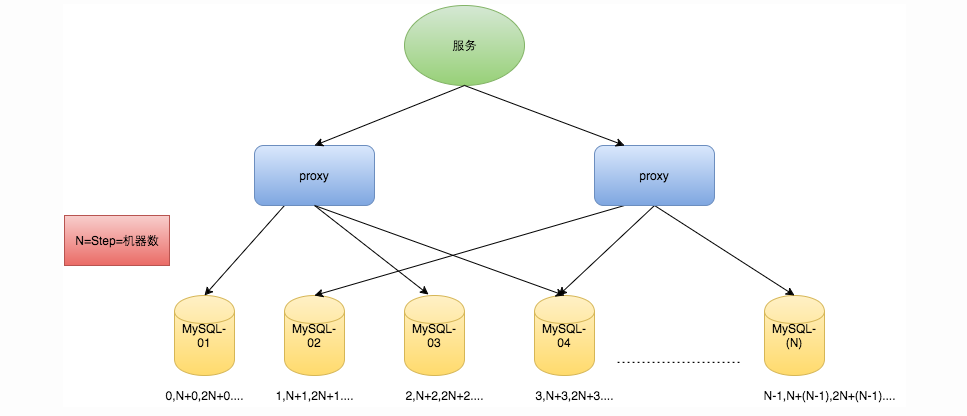
美团Leaf-segment方案直接取一批号段,用完再取一批号段,避免每次都去请求数据库导致连接数和线程数过大。
参考文档:
Mongdb objectID: https://docs.mongodb.com/manual/reference/method/ObjectId/#description
Leaf——美团点评分布式ID生成系统: https://tech.meituan.com/2017/04/21/mt-leaf.html
分布式ID生成 - 雪花算法: https://blog.csdn.net/u012488504/article/details/82194495
梅丽莎病毒: https://baike.baidu.com/item/梅丽莎病毒/9739231
mysql中InnoDB表为什么要建议用自增列做主键: https://www.cnblogs.com/moyand/p/9013663.html